-
Caracteres são representados computacionalmente usando o código ascii out utf
-
Número fixo de bits por caracter
-
Mapeamento um para um de caracter para um conjunto de bits
-
Total de bits = número de caracteres × bits por caracter
- Linguas no entanto tem um predominância do uso de alguns caracteres

- Ao contrário de "textos aleatórios", em que a distribuição é uniforme
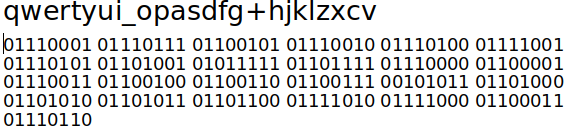
- Suponha que temos alguma distribuição a respeito do uso de caracteres
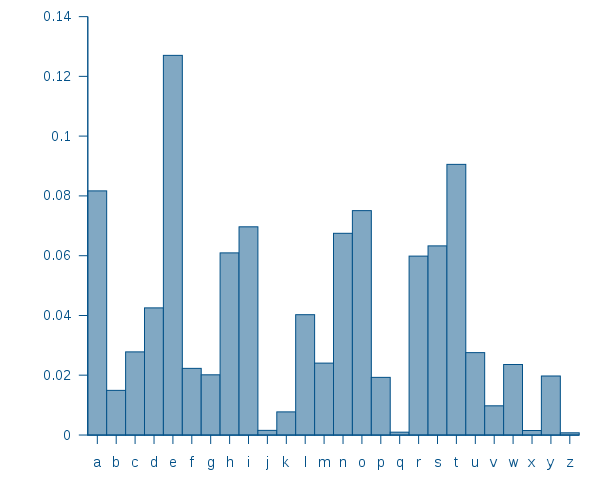
- Sem perda de generalidade, considere um alfabeto de 6 letras
- Como podemos codificar de maneira eficiente e não ambígua esses caracteres?
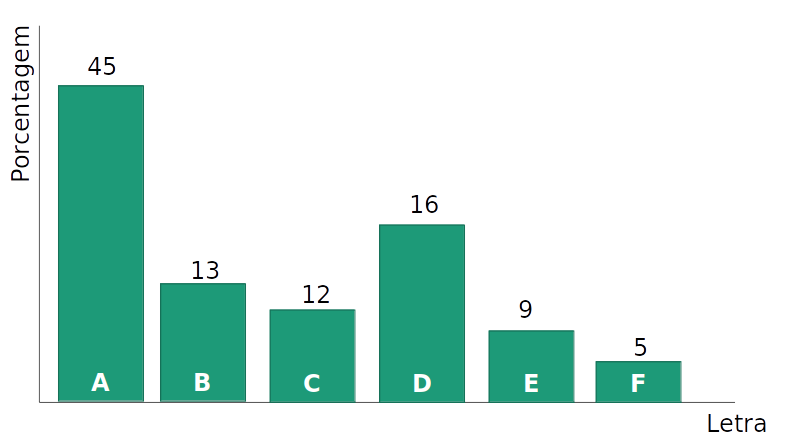
- Tentativa 1: Usando um número fixo de bits por caracter, os códigos
110 e 111 nunca são usados
- Uma representação compacta de 'A' economizaria espaço
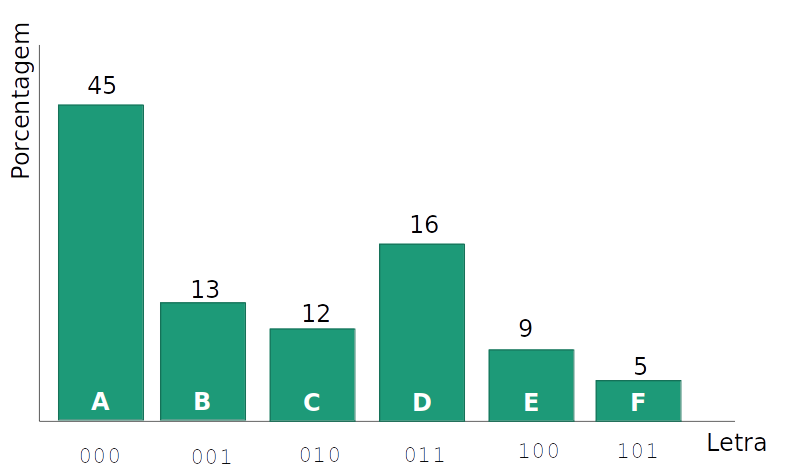
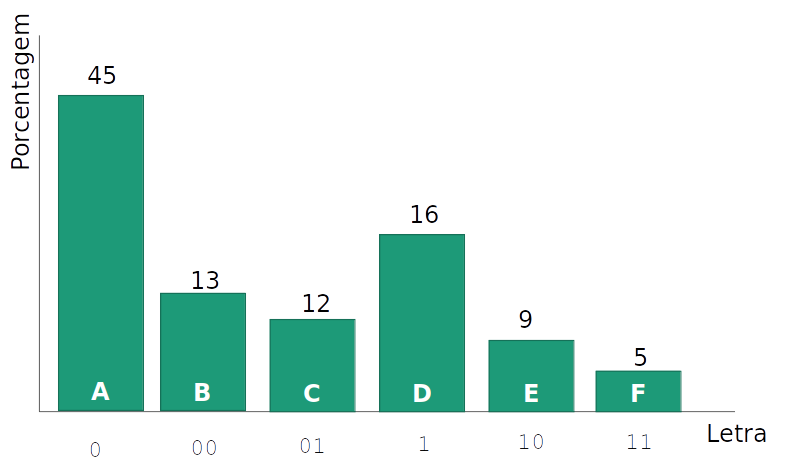
- Tentativa 2: Usando um número variável por caracter, em que as letras mais frequentes usam uma codificação menor, podemos ter ambiguidade
OOO significa 'AAA' ou 'AB' ?
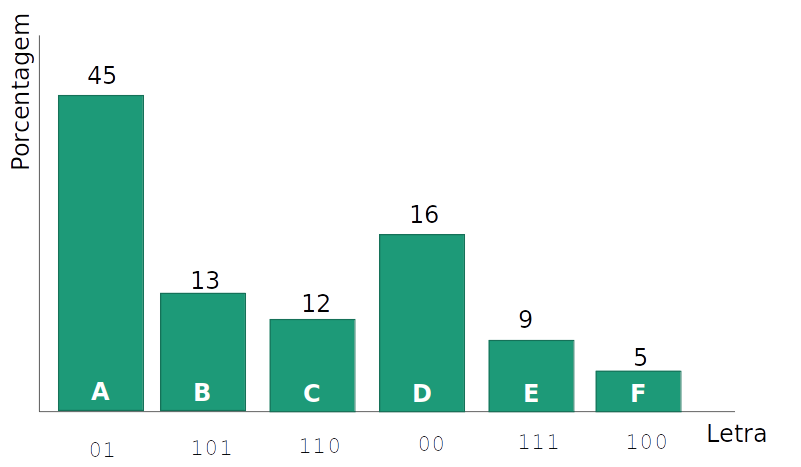
- Tentativa 3: Usando um número variável por caracter, em que as letras mais frequentes usam uma codificação menor, mas que nenhum código seja o prefixo de outro.
- Tente decodificar
10010101
-
Qual é a maneira mais eficiente de criar uma códificação livre de prefixos?
-
Como podemos usar o menor número possível de bits, sem criar um código ambíguo?
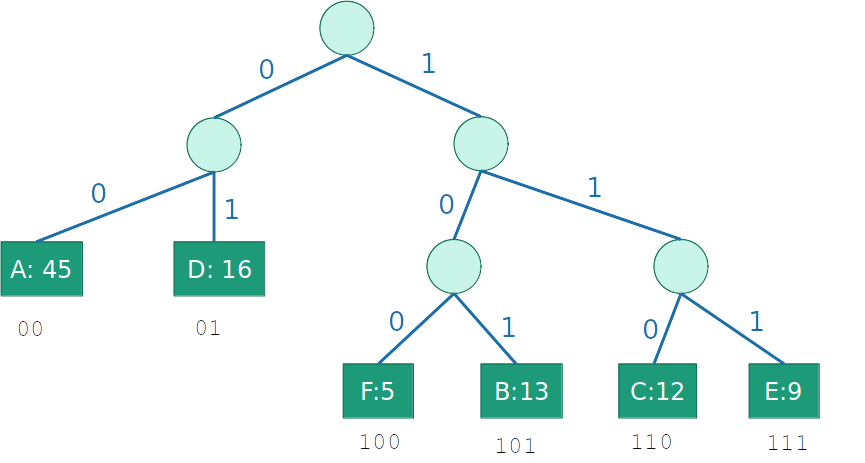
- Um código livre de prefixo pode ser represetado por uma árvore binária
- As letras aparecem nas folhas
- Uma ramificação à esquerda significa um '0', e a direita um '1'
- O código para uma letra é a concatenação dos bits da raíz a folha
C(T)=x∈folhas(T)∑P(x)⋅dT(x)
- Em que dT(x) é a distância da raíz até a folha (altura) do caracter 'x'
- No nosso exemplo:
C=2(0,45+0,16)+3(0,05+0,13+0,12+0,09)=2,39
- Dada uma distribuição P(x) sobre um conjunto de caracteres, como encontrar a árvore de custo mínimo?
C(T)minimo=minx∈folhas(T)∑P(x)⋅dT(x)
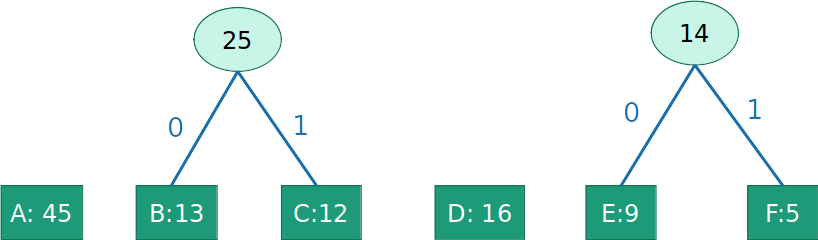
- Gulosamente construir sub-árvores de baixo para cima
- Objetivo guloso: letras menos frequentes devem aparecer mais abaixo na árvore
- Gulosamente construir sub-árvores de baixo para cima

- Gulosamente construir sub-árvores de baixo para cima
- Gulosamente construir sub-árvores de baixo para cima
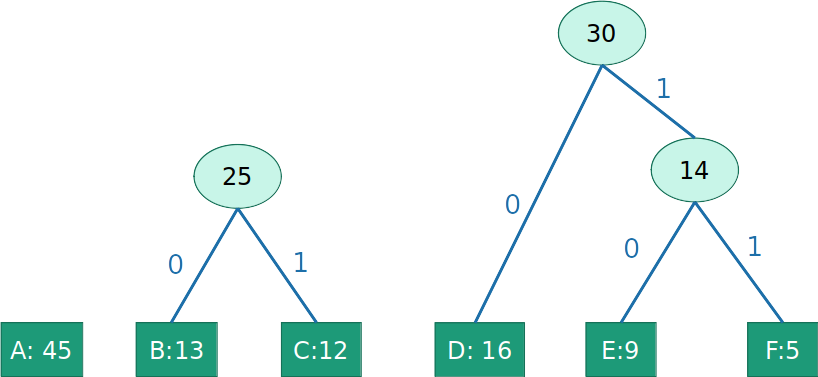
- Gulosamente construir sub-árvores de baixo para cima
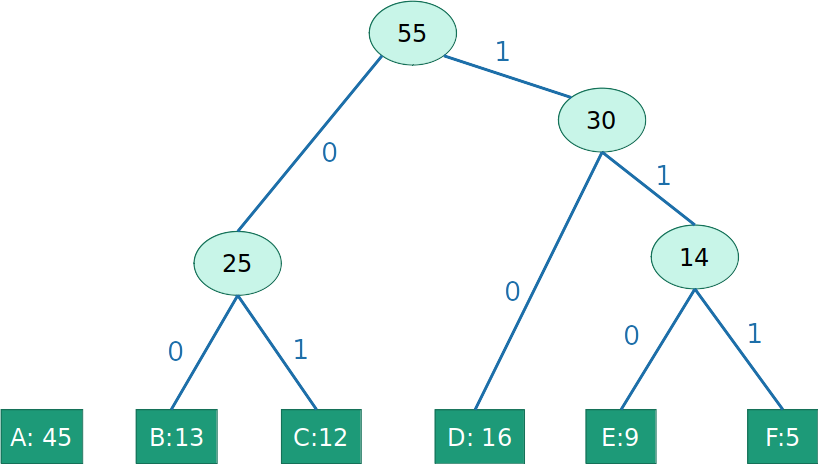
- Gulosamente construir sub-árvores de baixo para cima
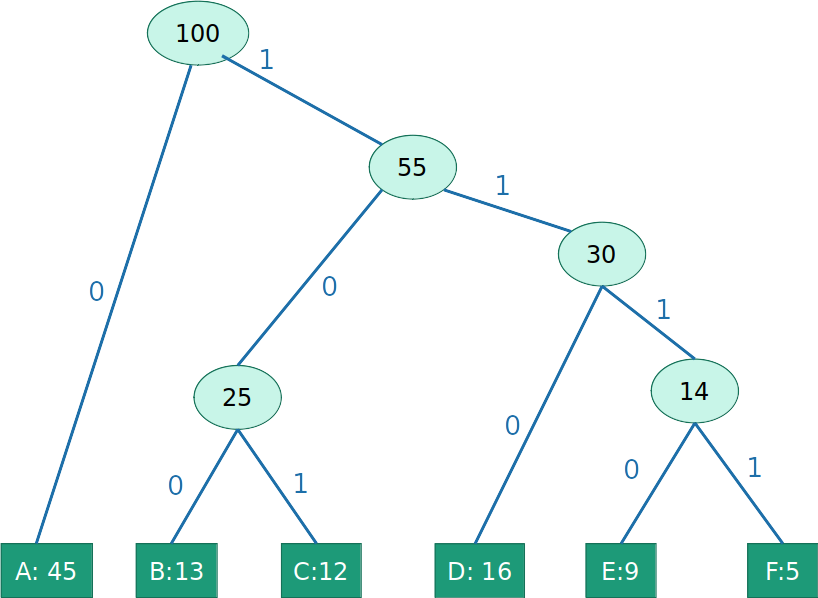
- Gulosamente construir sub-árvores de baixo para cima
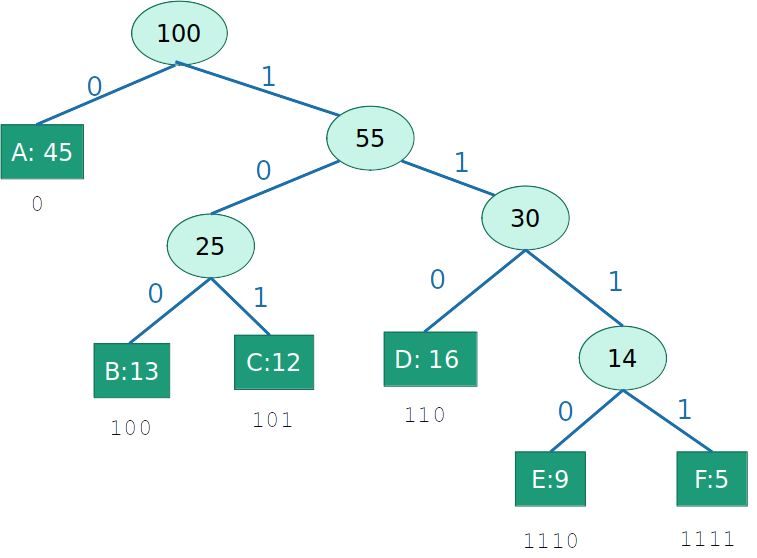
Custo=(0,45)+3(0,13+0,12+0,16)+4(0,09+0,05)=2,24
- Existe Θ(n) chamadas recursivas, pois essa é a quatidade de uniões que fazemos.
- Cada chamada pode levar Θ(n) para encontrar os elementos de menor frequência.
- Portanto, em uma implementação direta, o Algoritmos é Θ(n2)
- Entretanto, podemos usar uma heap para encontrar os elementos de menor frequência
- Dessa maneira, podemos encontrar os elementos de menor frequência em 2O(logn)=O(logn).
- A inserção da árvore unida na heap também pode ser feita em O(logn).
- Portanto, a complexidade usando heap é O(nlogn)
- A cada passo, não excluímos uma solução ótima
Lema 1: Suponha que x e y são as duas letras menos frequentes. Então existe uma árvore em que x e y são irmãos.
- Suponha que temos uma árvore ótima T, e um caracter 'a' tem uma frequência fa≥fx de 'x', mas dT(a) 'a' tem uma distância até a raiz maior que dT(x) de 'x'
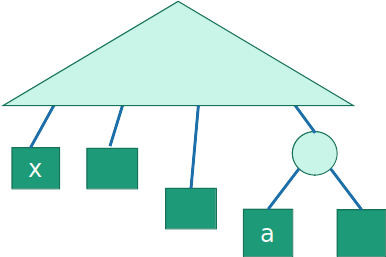
- Trocar 'a' por 'x' não pode aumentar o custo
- 'a' é mais frequente que 'x', e fizemos a sua codificação menor com a troca
C(T′)−C(T)=fxdT(a)+fadT(x)−fadT(a)−fxdT(x)=(fx−fa)(dT(a)−dT(x))≤0
- Repita o processo para 'y' até que tenhamos 'x' e 'y' como irmãos
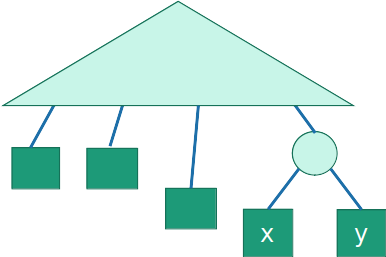
- Como 'x' e 'y' são as menos frequentes, o custo nunca aumentou. Então a árvore ainda é ótima
- O algoritmo funciona antes da primeira "junção". E após a junção, ainda funciona?
Lema 2: Uma árvore codificadora é ótima se e somente se a árvore codificadora da "combinação" de caracteres é ótima
- Em outras palavras, podemos considerar a "árvore atual" como contendo apenas folhas
- Alfabeto = {A,B,C,D,E,F}
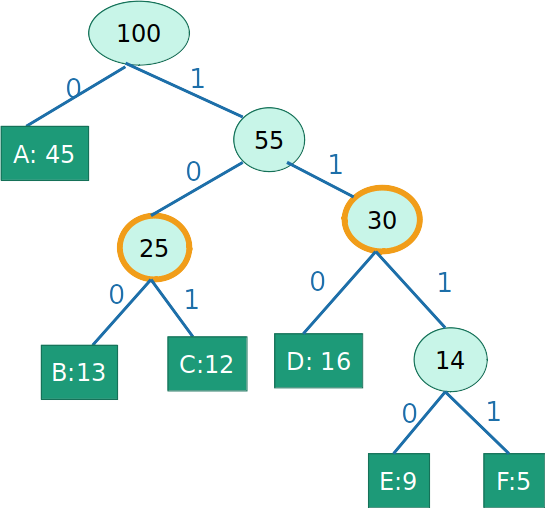
- Alfabeto = {A,G={B,C},H={D,E,F}}
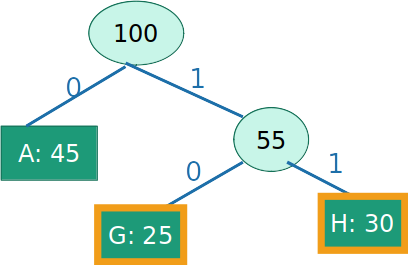
- Seja C um conjunto de caracteres, e T uma árvore que codifica C
- Seja C′ uma árvore em que que colapsa uma subárvore de C em um único caracter c′, com frequência fc′, e T′ uma árvore que codifica C′
- Seja C′′={c1′′,c2′′,⋯,cn′′} os caracteres da subárvore colapsados em c′, então fc′=∑inci′′
C(T)−C(T′)=c∈C∑f(c)⋅dT(c)−c∈C′∑f(c)⋅dT′(c)=(i=1∑rf(ci′′)dT(ci′′))−f(c′)dT′(c′)=(i=1∑rf(ci′′)(dT′′(ci′′)+dT′(c′))−f(c′)dT′(c′)=i=1∑rf(ci′′)dT′′(ci′′)+dT′(c′)i=1∑rf(ci′′)−f(c′)dT′(c′)=i=1∑tf(ci′′)dT′′(ci′′)
- A direfença de custo só depende de ci′′, então T é ótima se e somente se T′ é ótima
-
Lema 1 Suponha que 'x' e 'y' são os caracteres menos frequentes. Então tem uma árvore ótima em que 'x' e 'y' são irmãos.
-
Lema 2 Podemos assumir que a árvore atual contém apenas folhas
-
Então a cada passo não removemos nenhuma solução ótima
- Suponha que após o passo t−1 temos uma coleção de sub-árvores que podem ser interpretadas como "folhas" (de acordo com o Lema 2), e que fazem parte da árvore ótima
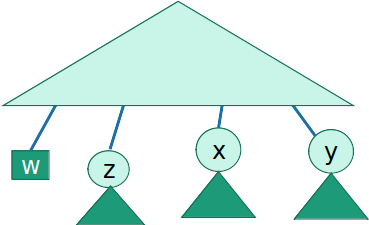
- Queremos mostrar que após o passo t contendo todas as subárvores como "folhas" que fazem parte da árvore ótima
-
Digamos que 'x' e 'y' são as duas menores (menos frequentes)
-
De acordo com o Lema 1, existe uma sub-árvore ótima em que 'x' e 'y' são irmãos
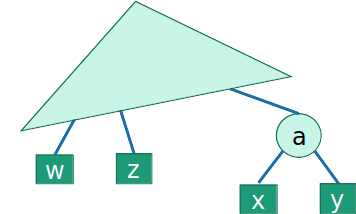
- E no passo t, o algoritmo une as subárvores com raíz em 'x' e 'y', criando uma nova subárvore:
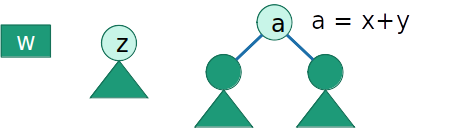
- De acordo com o Lema 2, o novo nó 'a' pode ser interpretado como uma folha, com frequência fa=fx+fy. Portanto, após o passo t, continuamos com as subárvores que fazem parte da árvore ótima.
- O código ASCII não é uma maneira ótima de codificar textos em línguas baseadas em alfabetos em que a distribuição das letras não é uniforme.
- A codificação de Huffman é uma maneira ótima!
- Podemos usar um algoritmo guloso para calcular a codificação de Huffman para qualquer língua.
