- Armazena uma tabela com solução de (sub)problemas já resolvidos
- Essa estratégia é chamada de memorização
- Usa as soluções da tabela para resolver problemas ainda não resolvidos
- Ao final, usamos a informação coletada no caminho para resolver o problema completo
- O nome "dinâmica" se refere ao fato que o problema é resolvido em multiplos estágios
- O nome foi atribuído (junto com a criação da técnica) nos anos de 1950
- Precisava de um "nome bonito" para conseguir financiamento da força aérea americana:
“It’s impossible to use the word, dynamic, in the pejorative sense...I thought dynamic programming was a good name. It was something not even a Congressman could object to.”
-
A sequência BDFH é uma subsquência de ABCDEFGH
- Observe que não precisam, necessariamente, serem contínuos
-
Se X e Y são sequências, uma subsequência comum é uma subsequência de ambas as sequências.
- BDFH é uma subsequência de ABCDEFGH e ABDFGHI
-
A maior subsequência comum é uma sequência que é comum e é a mais longa.
- A maoir subsequência comum entre ABCDEFGH and ABDFGHI é ABDFGH.
-
Problema: Dados duas sequências X={X1,X2,⋯,Xm} e Y={Y1,Y2,⋯,Yn}, encontrar uma subsquência de maior tamanho LCS(X,Y)
- Bioinformática:
- Encontrar a semelhança genética entre espécies; Encontrar sequências comuns para uma detarminada característica/doença genética
- Diferença entre arquivos:
- Merge em controlo de versões
- Processamento de Língua Natural
-
Solução por força bruta:
- Enumerar todas as possíveis subsequências de X. Checar se cada uma dessas subsquências também é subsequência de Y, guardando a de maior comprimento.
-
Complexidade?
- Existem 2m subsequências de X
- Tempo linear para verificar se a subsequência de X está em Y
- O(n2m), portanto ineficiente
- Identificar subestrutura ótima
- Encontrar uma formulação recursiva
- Usar programação dinâmica para encontrar o valor da função ótima
- Se necessário, armazenar informação adicional de tal maneira que no passo 3 podemos encontrar a solução ótima
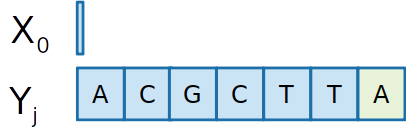
- Vamos definir um prefixo como uma subsequência que se inicia na primeira, até uma certa posição i
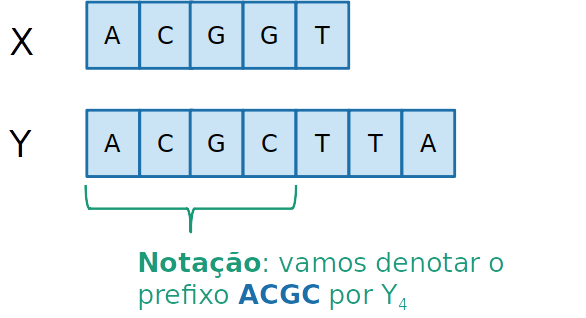
- Seja C[i,j] o tamanho da maior subsquência comum entre Xi e Yj
C[4,4]=3
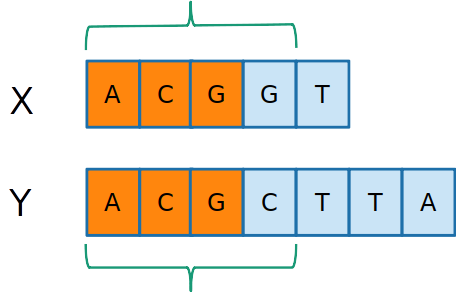
- Seja C[i,j] o tamanho da maior subsquência comum entre Xi e Yj
C[2,3]=4
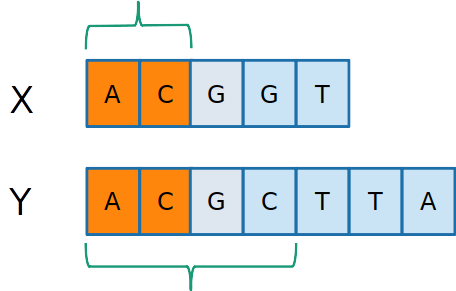
-
Seja X e Y duas sequências de tamanho i e j, nas quais queremos encontrar a maior sequência comum.
-
Vamos tentar escrever C[i,j] em função de problemas menores
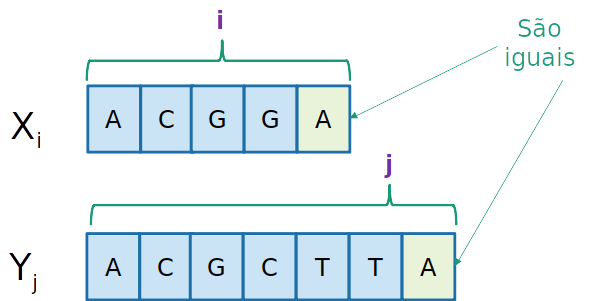
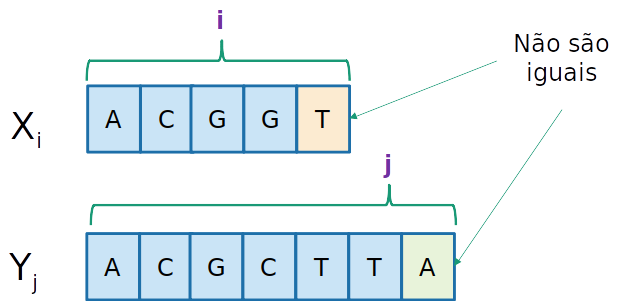
- Seja X[i] e Y[j] os dois últimos caracteres da sequência:
Ci,j=⎩⎪⎨⎪⎧01+Ci−1,j−1max(Ci−1,j,Ci,j−1)se i=0 ou j=0se X[i]=Y[j]se X[i]=Y[j]
- Se X[i]=Y[j], então
Ci,j=1+Ci−1,j−1
uma vez que as duas últimas posições são iguais (portanto a subsequência máxima entre os dois últimos caracteres é 1),
- Se i=0 ou j=0, então C[i,j]=0 uma vez que
- Ou X ou Y não contém nenhum caracter, e não tem nenhuma subsequência em comum.
- Se X[i]=Y[j], então Ci,j=1+Ci−1,j−1
uma vez que
- as duas últimas posições são iguais (portanto a subsequência máxima entre os dois últimos caracteres é 1),
- e devemos continuar verificando o restante da subsquência
- Se X[i]=Y[j], então max(Ci−1,j,Ci,j−1) uma vez que
- A subsequência máxima pode se dar ignorando o último caracter da primera sequência
- A subsequência máxima pode se dar ignorando o último caracter da segunda sequência
-
Uma LCS(X,Y) pode ser obtida recursivamente da seguinte maneira:
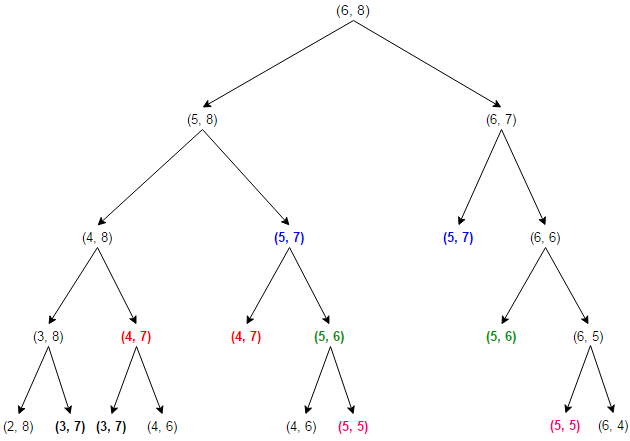
- Se Xm=Yn, eles fazem parta de LCS, e deve-se continuar procurando em LCS(Xm−1,Yn−1)
- Se Xm=Yn, então temos dois subproblemas
- Encontrar uma LCS(Xm−1,Yn);
- Encontrar uma LCS(Xm,Yn−1);
- LCS(X,Y) é a maior entre essas duas.
-
A complexidade desse algoritmo é O(2(m+n))
- Observe também que há um overlap entre os subproblemas
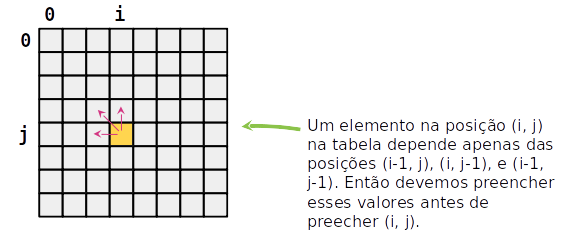
- Assim com no problema da mochila inteira, vamos usar uma matriz para armazenar os valores de Ci,j já calculados
Ci,j=⎩⎪⎨⎪⎧01+Ci−1,j−1max(Ci−1,j,Ci,j−1)se i=0 ou j=0se X[i]=Y[j]se X[i]=Y[j]
- A matriz é criada com uma linha e coluna a mais, inicialmente preenchida com zeros
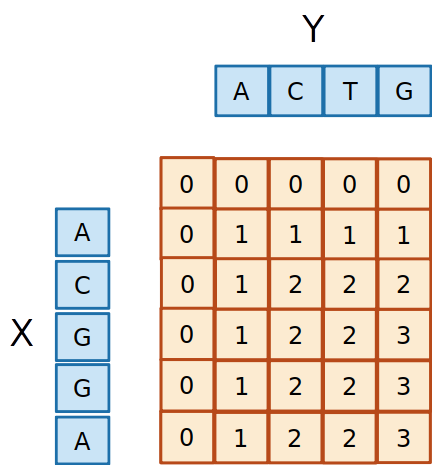
- Preenchemos a matriz de acordo com os três casos possíveis até completar a matiz
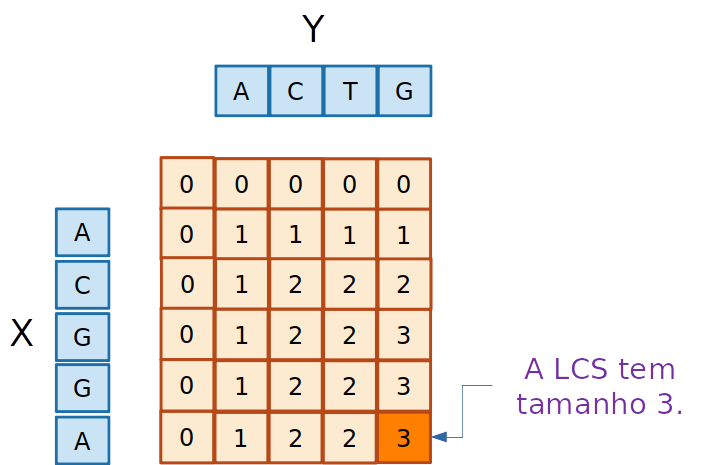
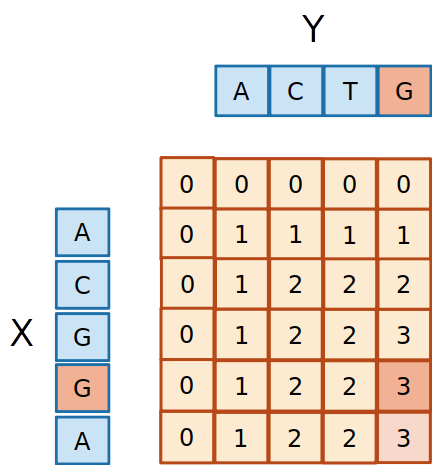
- O tamanho da maior subsequência comum está na última posição da matriz
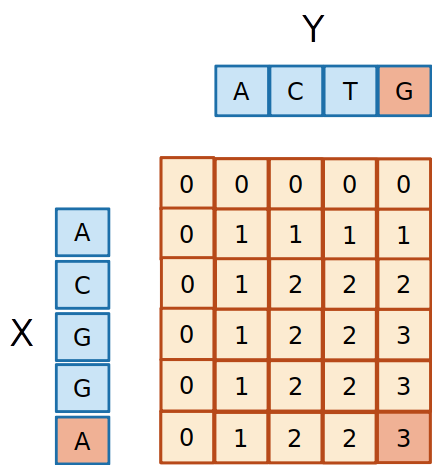
- Os dois caracteres são diferentes, então o
3 deve ter vindo do 3 de cima
- Os dois caracteres são iguais, então o
3 deve ter vindo desta célula
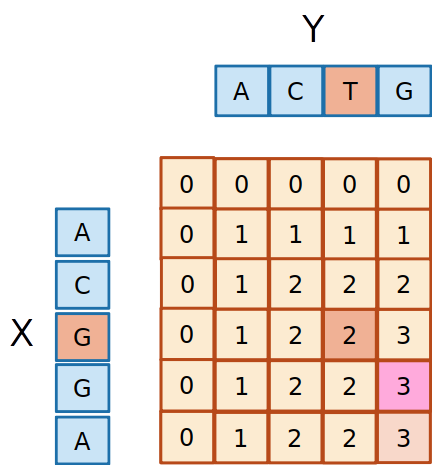
- Como a última iteração foi um match, devemos nos mover na diagonal
- Como os dois elementos são diferentest, o
2 pode ter vindo tanto da esquerda quanto de cima
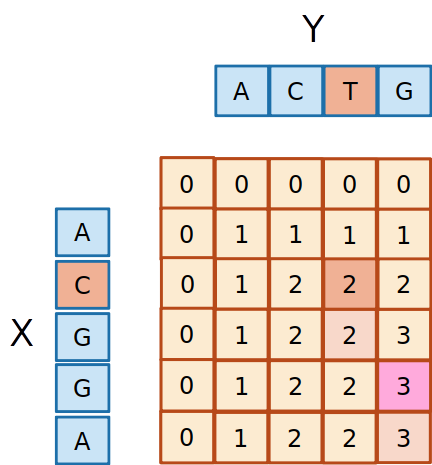
- Digamos que escolhemos a de cima
- Como os dois caracteres são diferentes, e o valor da célula de cima é menor que o da esquerda, o
2 deve ter vindo da esquerda
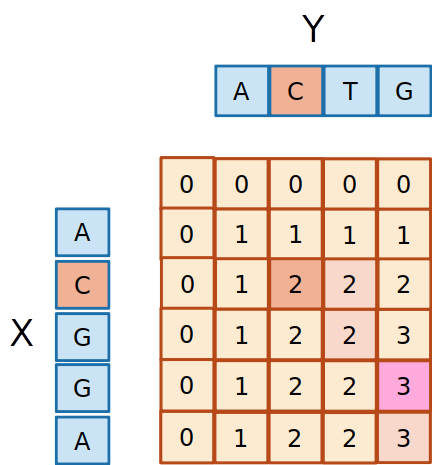
- Os dois caracteres são iguais, então o
2 deve ter vindo desta célula
- Os dois caracteres são iguais, então o
1 deve ter vindo desta célula
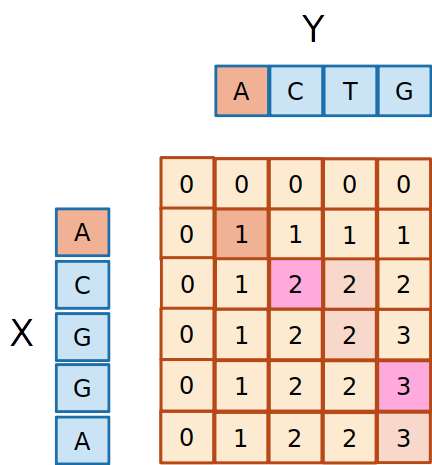
- Chegamos ao final das duas subsequências, a maior subsequência comum correspondem aquelas em houve um match. Nesse caso, ACG
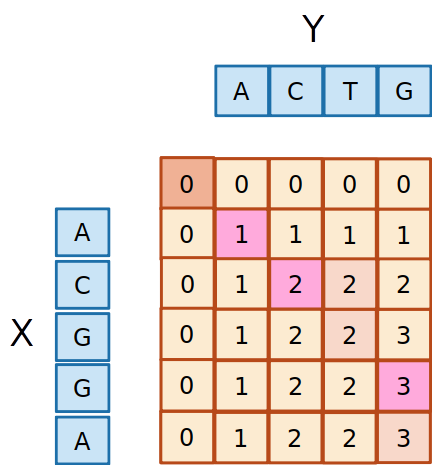
- É fácil ver que a complexidade do algoritmo é O(mn), com um custo adicional de memória de O(mn)
- Quando dois caracteres são iguais, temos um
match
- Quando há um buraco, temos um
gap
- Em algumas situações, queremos dar pesos diferentes ao
match e ao gap
- Esse é um requisito comum em análise de DNA, em que queremos evitar buracos muito grandes no aninhamento
- Eventualmente, podemos também permitir
match por similaridade
- Por exemplo,
s e z tem um som parecido
-
Seja α(a,b) uma função que retorna o benefício/penalidade de alinhar os caracteres a e b (que podem ou não serem iguais)
-
Seja α(gap) a penalidade de alinhar um caracter com um gap
-
O Algoritmo de Needleman-Wunsch é similar ao algoritmo de encontrar uma subsequência máxiama, mas com o objetivo é encontrar o alinhamento de pontuação máxima
- Para o algoritmo de Needleman-Wunsch, definimos uma matriz de pontuação em que os pesos são definidos por
Pi,j=max⎩⎨⎧α(xi,yj)+Pi−1,j−1α(gap)+Pi−1,jα(gap)+Pi,j−1
- É fácil ver que a complexidade é a mesma do algoritmo que encontra a maior subsquência máxima


