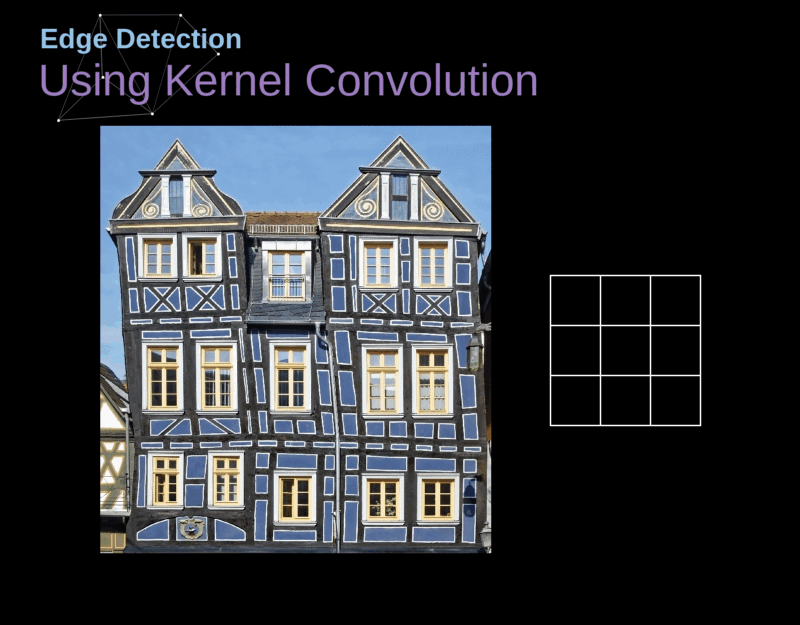
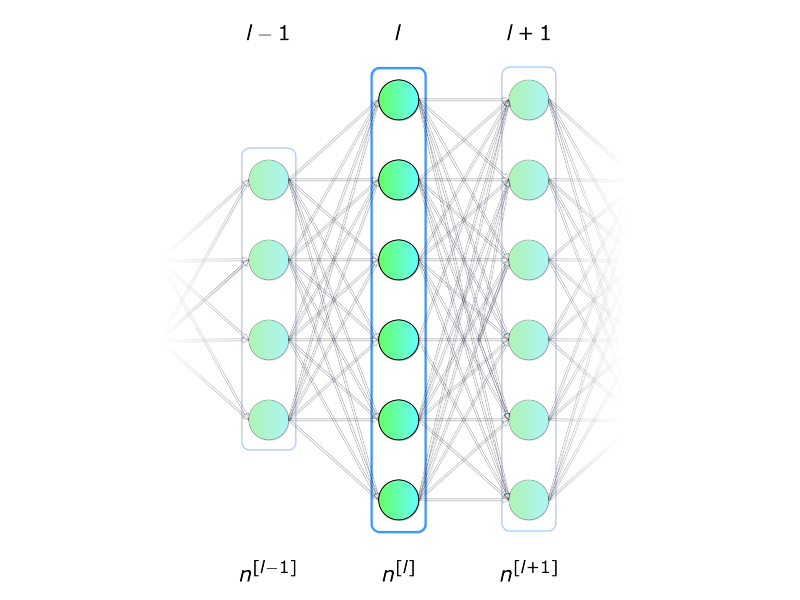
- Em aulas passadas, nós vimos a rede MLP, que é uma rede densamente conectada
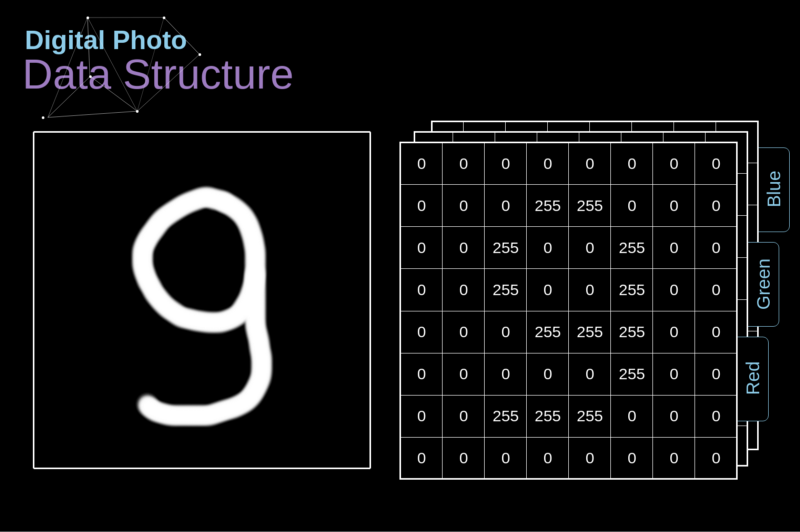
- Em muitos problemas, como imagens ou séries temporais, o tamanho da entrada é enorme:
- Um celular com uma resolução de 12MP tem 36M de elementos
- Uma rede neural com uma única camada de 100 neurônios teria 3.6 bilhões de parâmetros
-
Quantidade grande de parâmetros
-
Inadequadas a imagens de alta resolução
-
Tempo para computar as ativações/pré-ativações.
-
Ignoram a estrutura espacial existente em imagens
-
Se as imagens são linearizadas os pixels próximos e os localizados em regiões distantes tratados indistintamente.
-
A própria rede teria que detectar as dependências existentes na estrutura espacial da distribuição próximas às imagens de entrada.
- Uma rede desse tamanho poder ter problemas para convergir
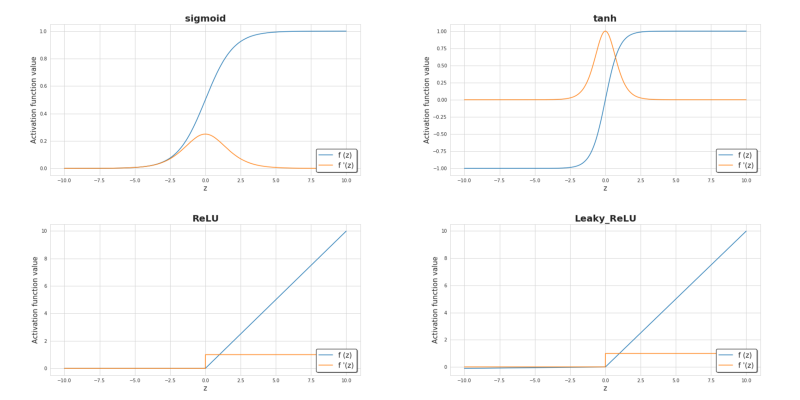
- "Desaparecimento do gradiente": gradiente fica muito pequeno (muito próximo de zero) - muito tempo e muitos dados para treinar
- "Explosão do gradiente": gradiente muito grande que não converge
- Usar outras funções pode ajudar a evitar evitar o desaparecimento do gradiente
- A função de ativação RELU (rectified linear unit) evita o desaparecimento do gradiente
- Entretanto, pode "matar" a entrada (maioria das saídas é igual a zero)
-
Conceitos:
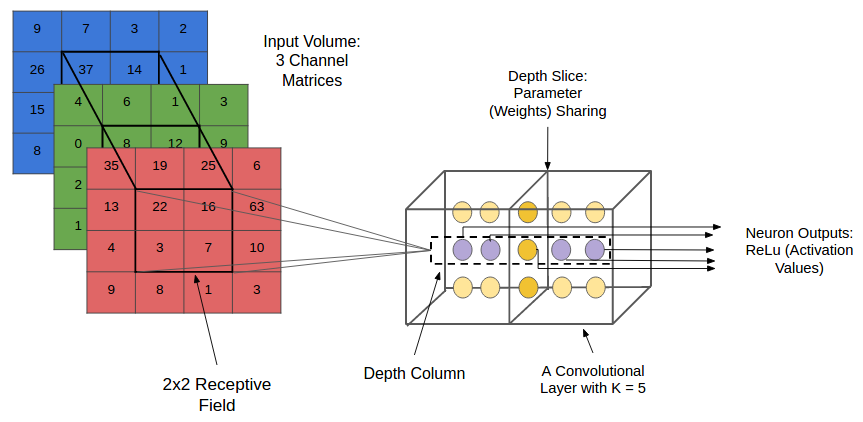
- campos receptivos locais (local receptive fields)
- mapas de características (feature maps, activation maps)
- compartilhamento de pesos (shared weights).
-
Operações
- convolução (convolution)
- subamostragem (subsampling, pooling)
- zero-padding
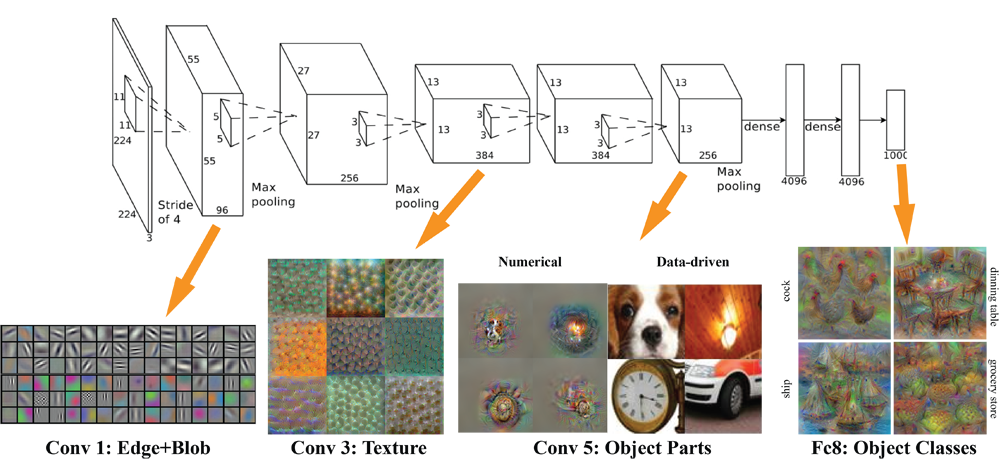
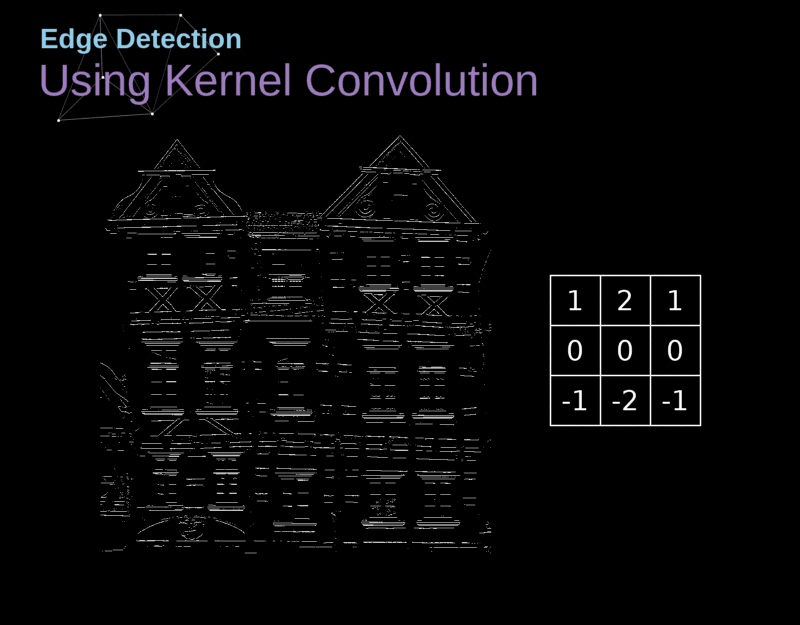
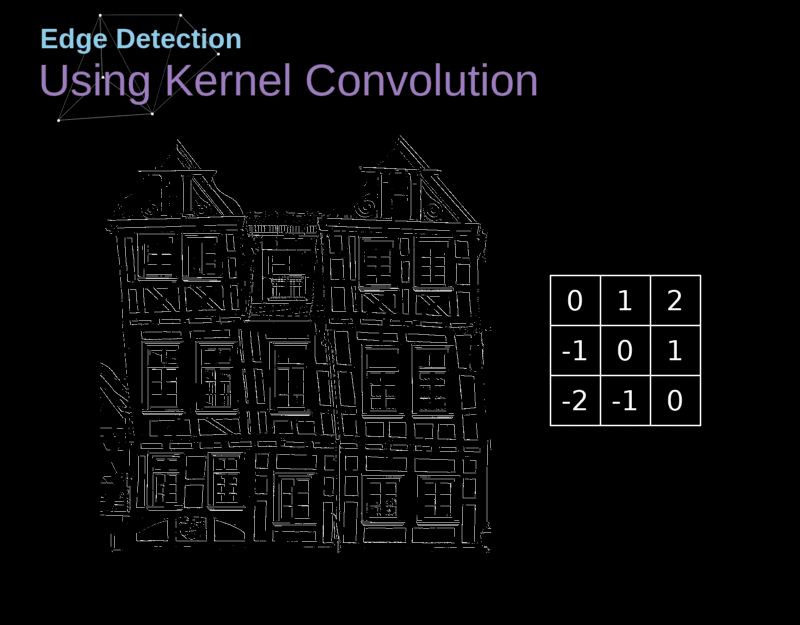
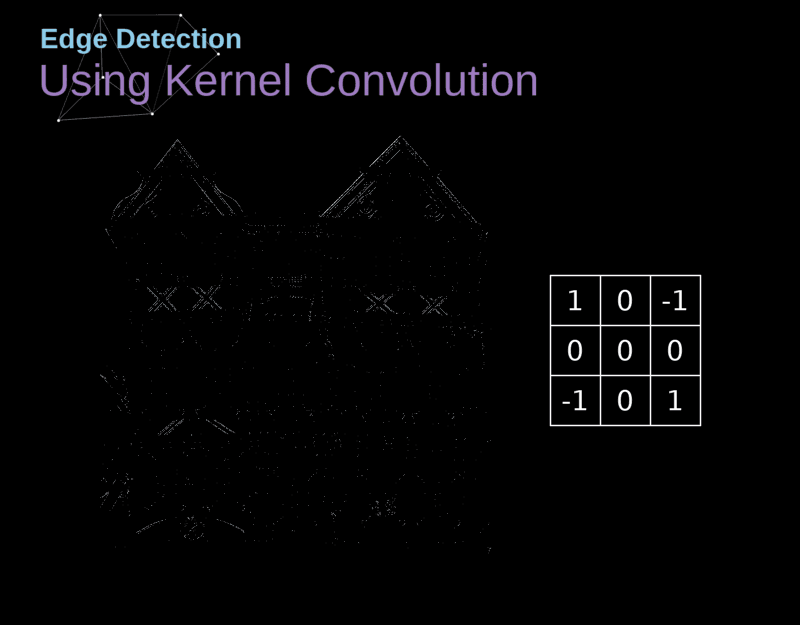
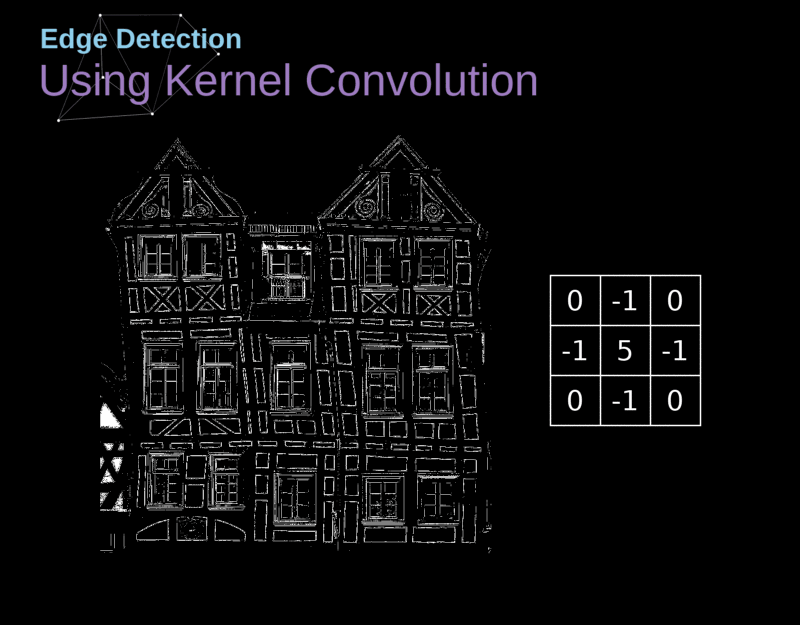
- Por meio de seu campo receptivo, cada neurônio pode detectar características visuais elementares
- (e.g., arestas orientadas, extremidades, cantos)
- ... que podem então ser combinadas por camadas subsequentes para detectar características visuais mais complexas
- (e.g., olhos, bicos, rodas, etc.)
-
O tipo de camada principal em uma CNN é a camada de convolução (convolution layer, CONV).
-
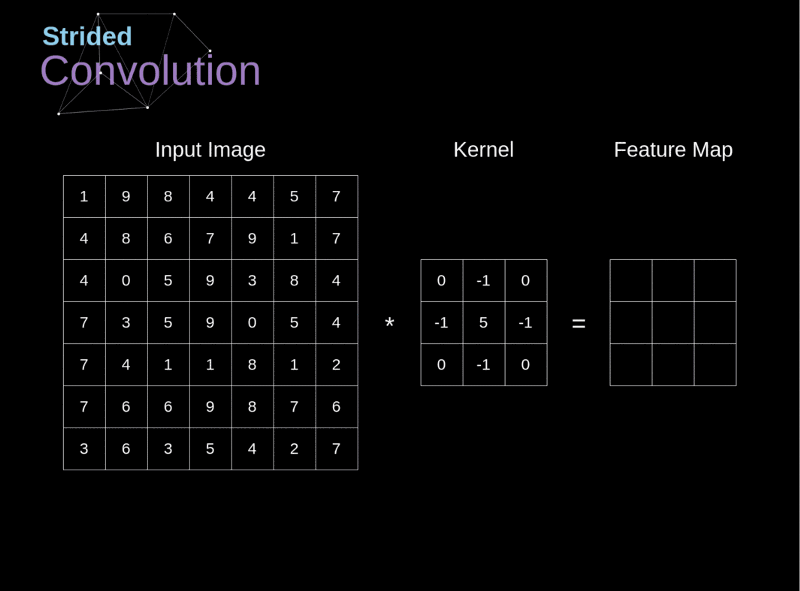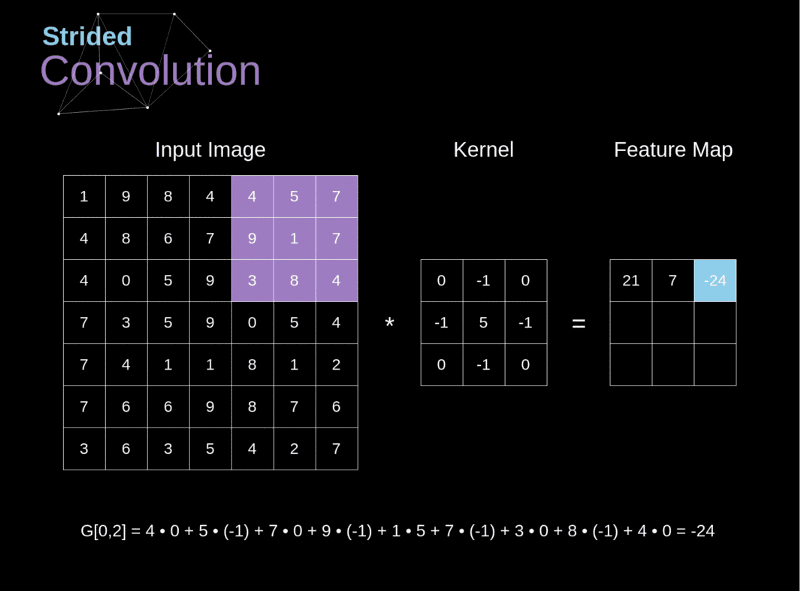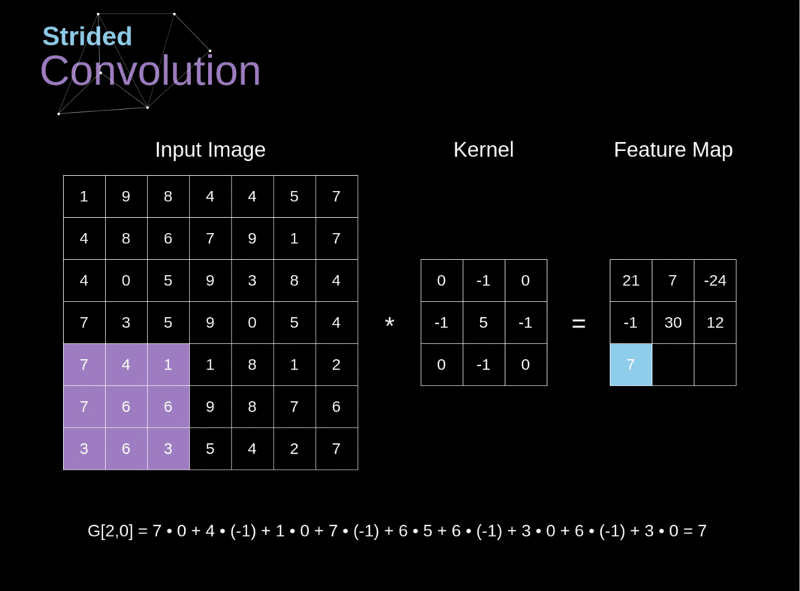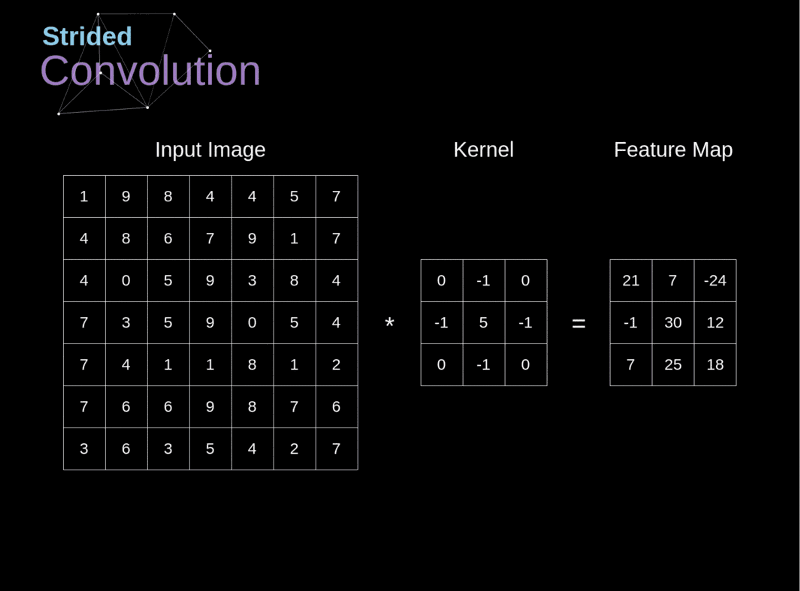
Cada neurônio em uma CONV aplica um operador de convolução (filter, kernel) sobre seu campo receptivo.
-
Um operador de convolução é uma matriz!
- Objetivo: extrair características(features) da imagem de forma automática durante o treinamento.
-
Analogia: a convolução corresponde a mover uma lanterna da direita para a esquerda, e de cima para baixo, até chegar ao canto inferior direito da imagem de entrada.
-
A cada região iluminada, o filtro da convolução é aplicado na tentativa de detectar alguma característica visual.
-
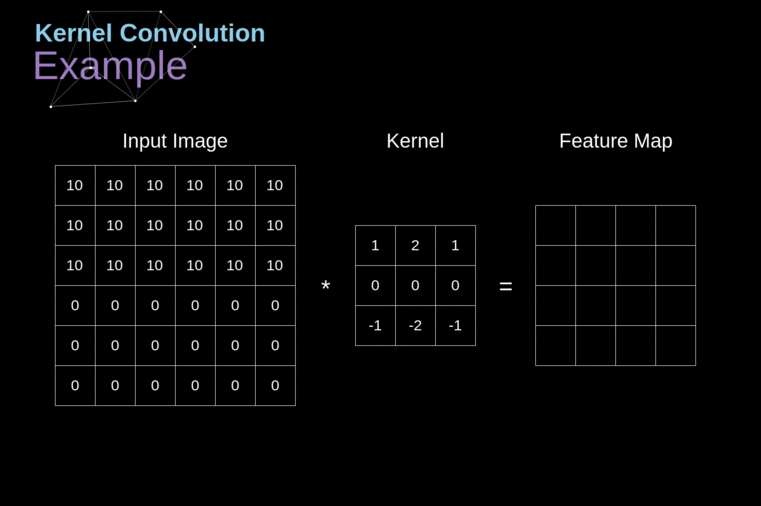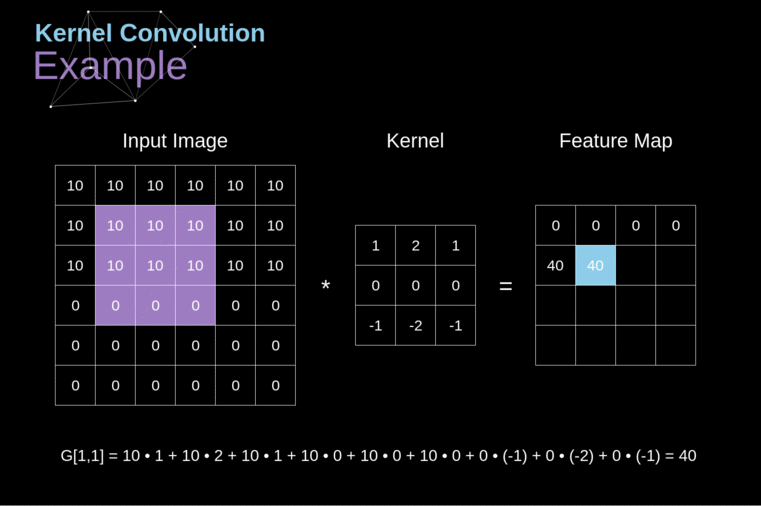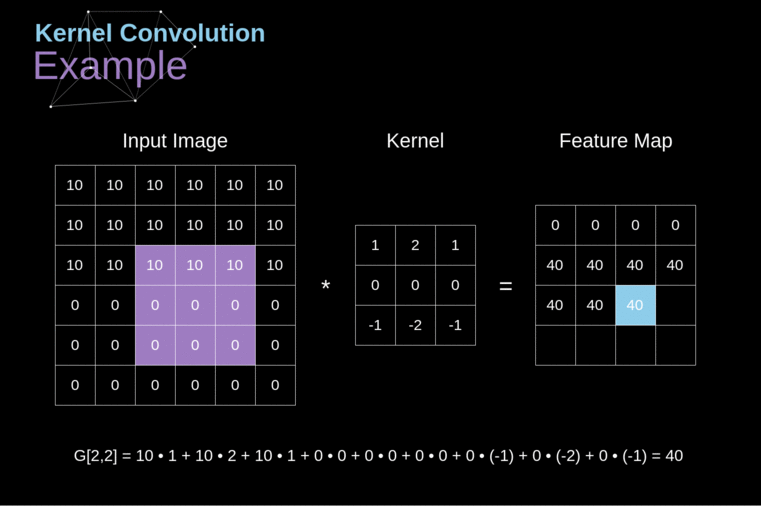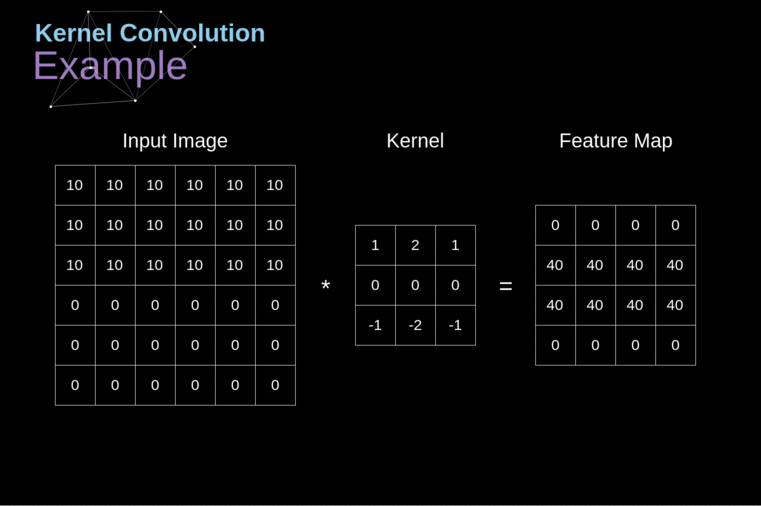
No contexto de uma CNN, a aplicação de uma convolução corresponde a computar o produto escalar (dot product) entre a entrada e o filtro.
-
A definição geral é mais complexa...
-
Resultado: outra matriz!
- mapa de ativação (activation map) ou mapa de características (feature map)
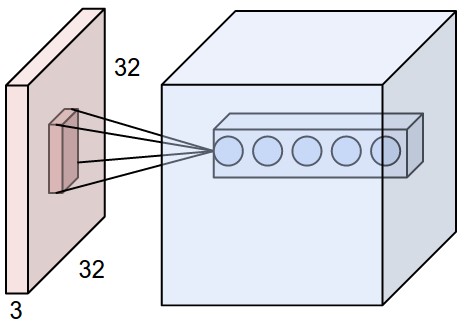
- Uma CONV é um arranjo tridimensional (tensor) de neurônios: altura, largura, profundidade.
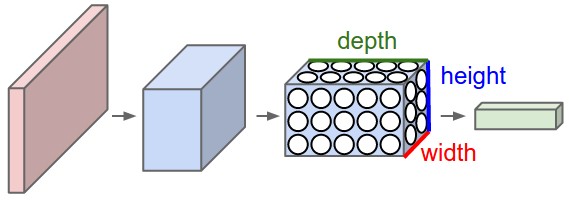
-
Os neurônios em uma CONV aplica um filtro (operação de convolução) ao
seu campo receptivo
-
Neurônios de uma mesma camada de profundidade aplicam o mesmo filtro.
-
O objetivo de cada filtro é ativar quando detecta um tipo particular de característica na entrada.
- Durante a propagação adiante (forward pass), cada filtro é aplicado (convolved) através do volume de entrada.
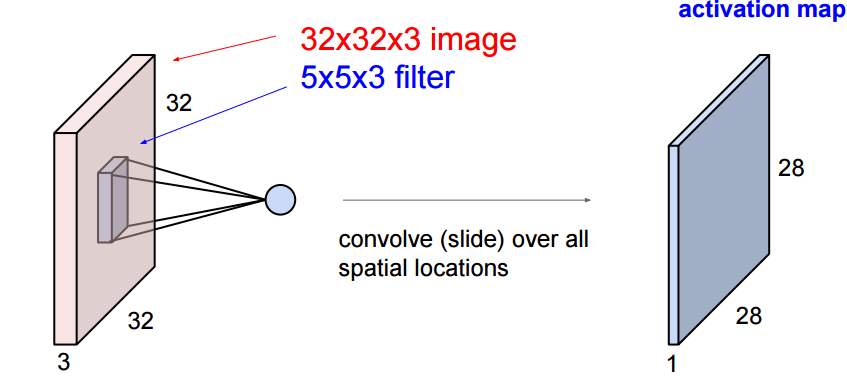
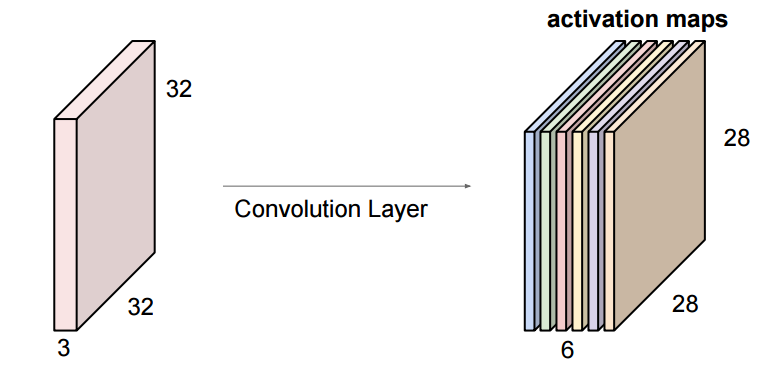
- O volume de saída de uma CONV é uma sequência de mapas de ativação
- A sequência de mapas de ativação de um volume forma a dimensão de profundidade (depth) desse volume.
-
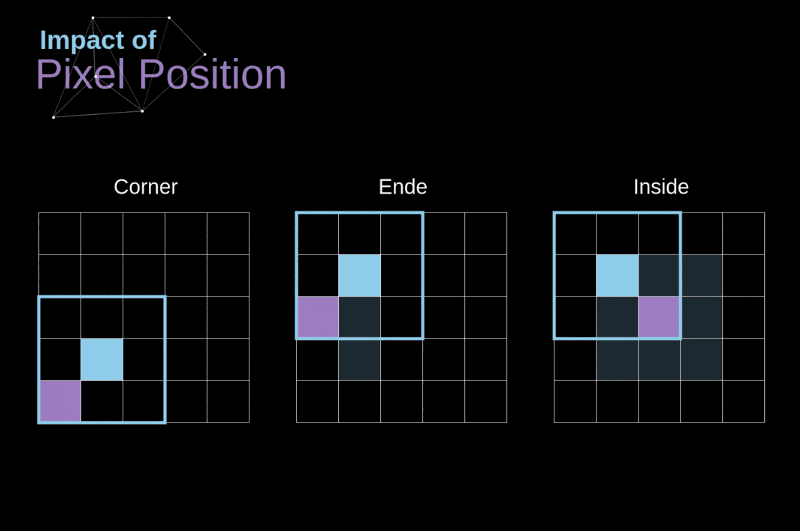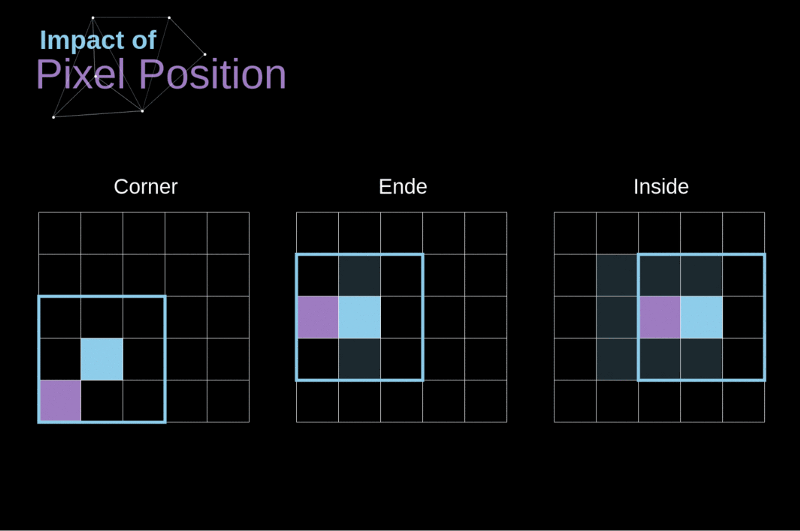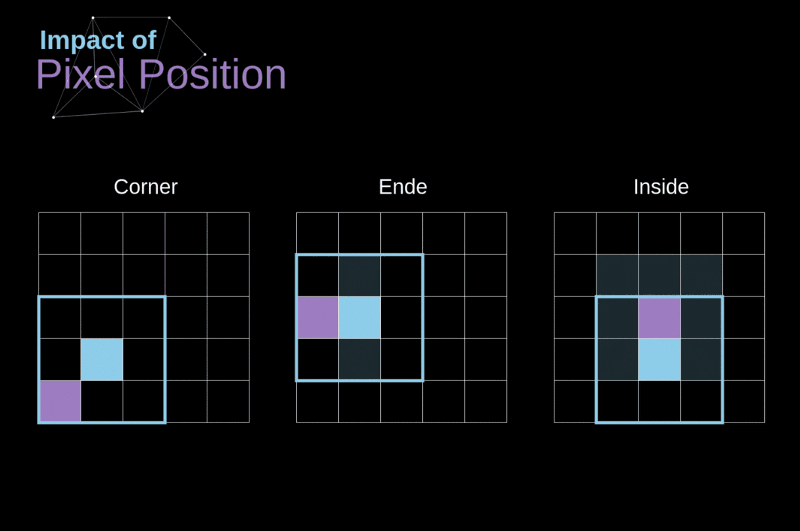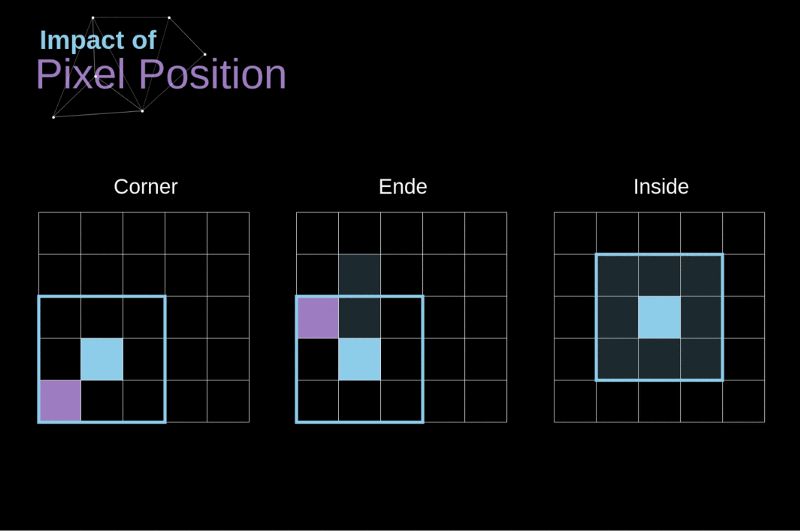
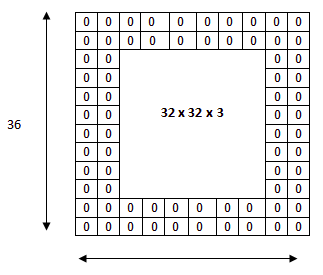
As convoluções utilizam de maneira diferente os elementos que estão nos cantos, bordas e no meio da imagem
-
Os elementos dos cantos e bordas podem ser "subutilizados"
Uma imagem com 32x32 pixels é preenchida com zeros para aplicar uma máscara de 3x3
- O passo (stride, S) é um hiperparâmetro que controla de que forma o filtro é “deslizado” pelo volume de entrada durante a convolução
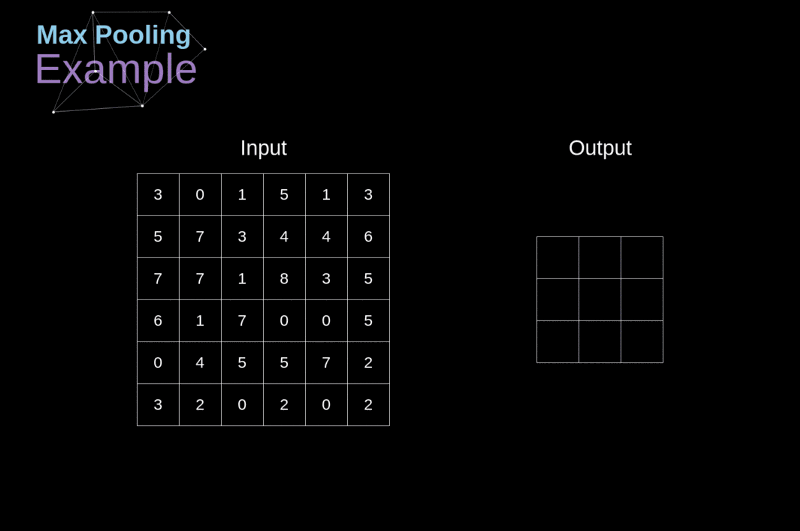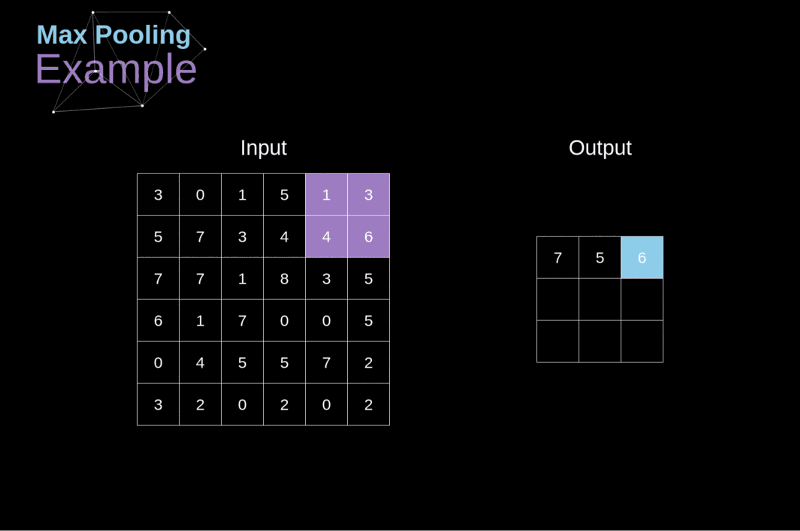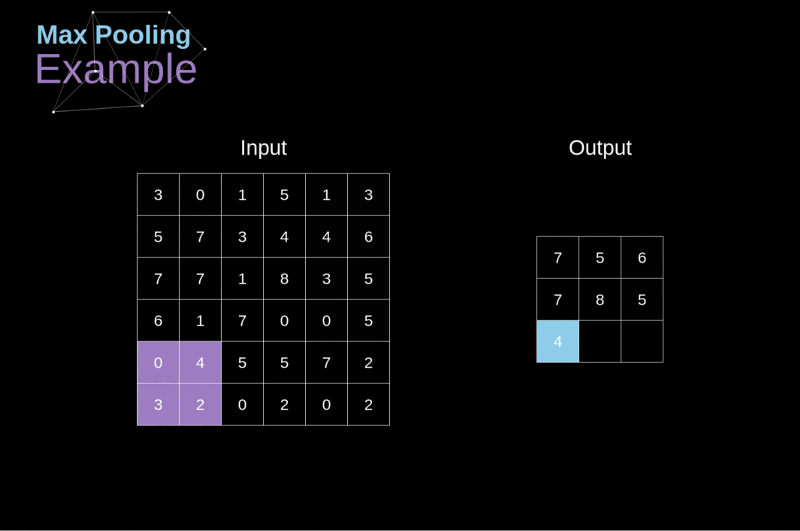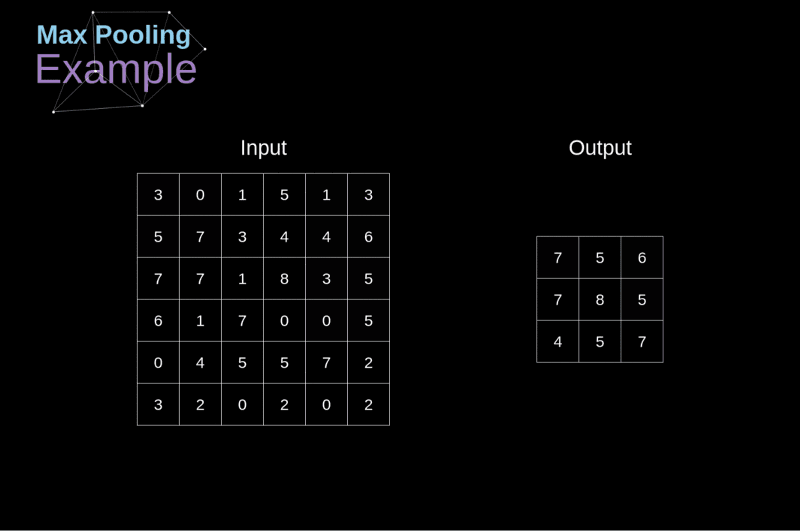
- Por vezes encontrada entre duas camadas CONVs sucessivas para reduzir a complexidade do modelo (mitigar overfitting).
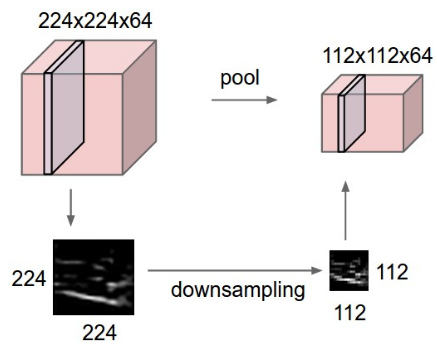
- Objetivo: reduzir dimensões espaciais (largura x altura) do volume de entrada para a próxima CONV.
- Aplicada a cada fatia de profundidade do volume de entrada.
- Profundidade do volume de saída igual à do volume de entrada.
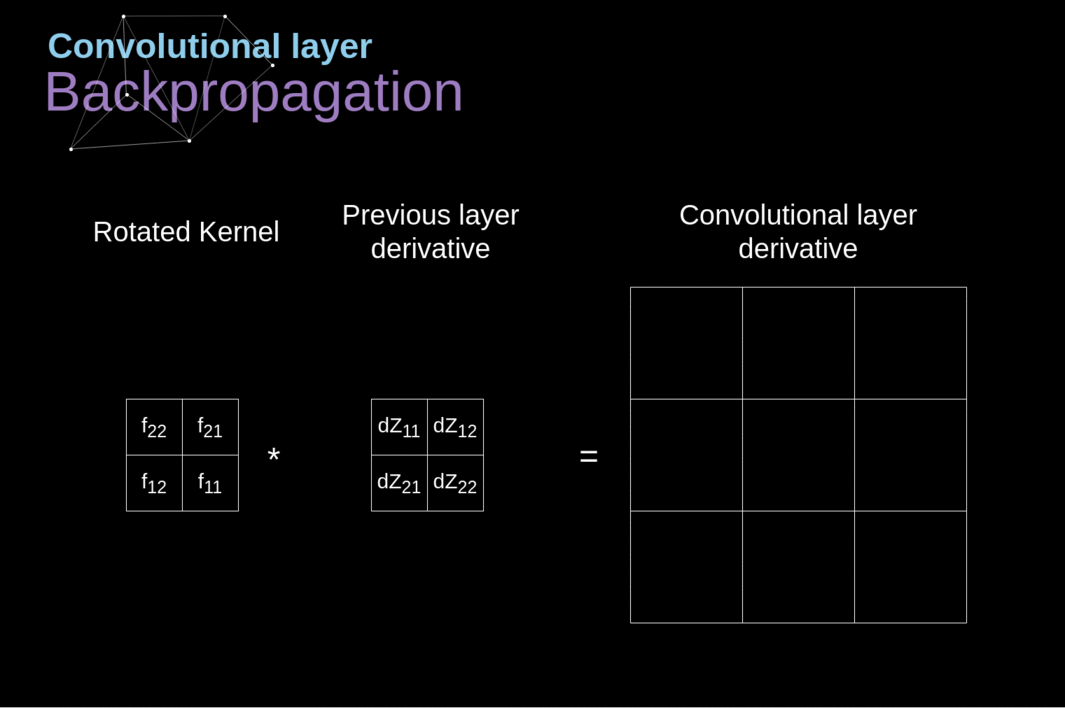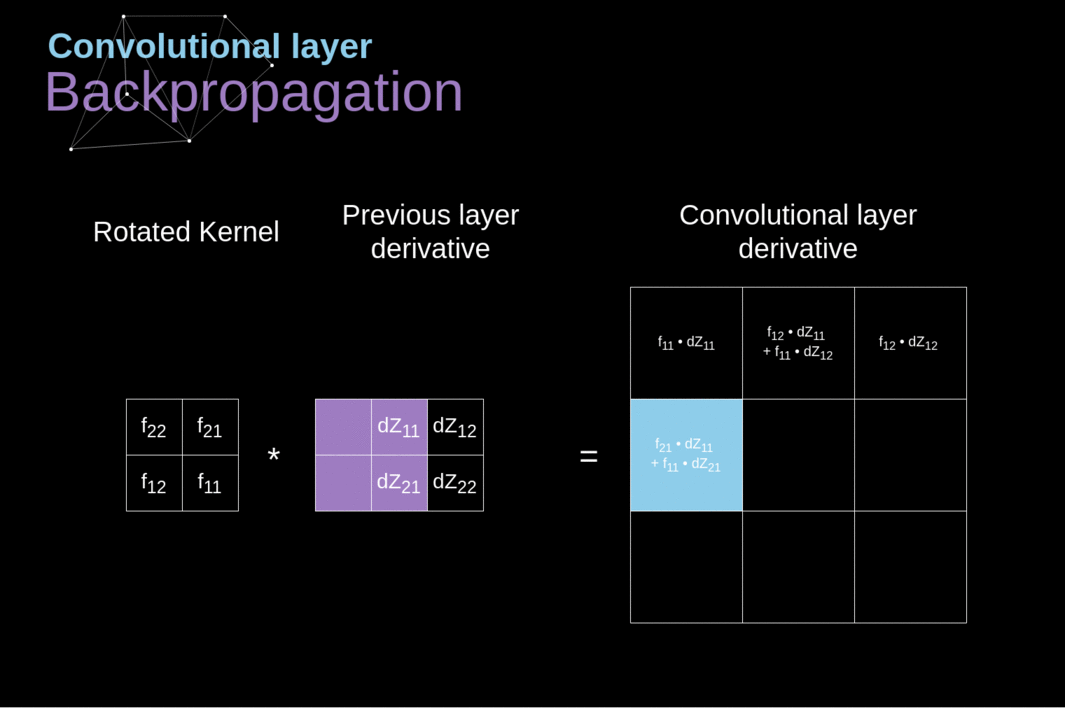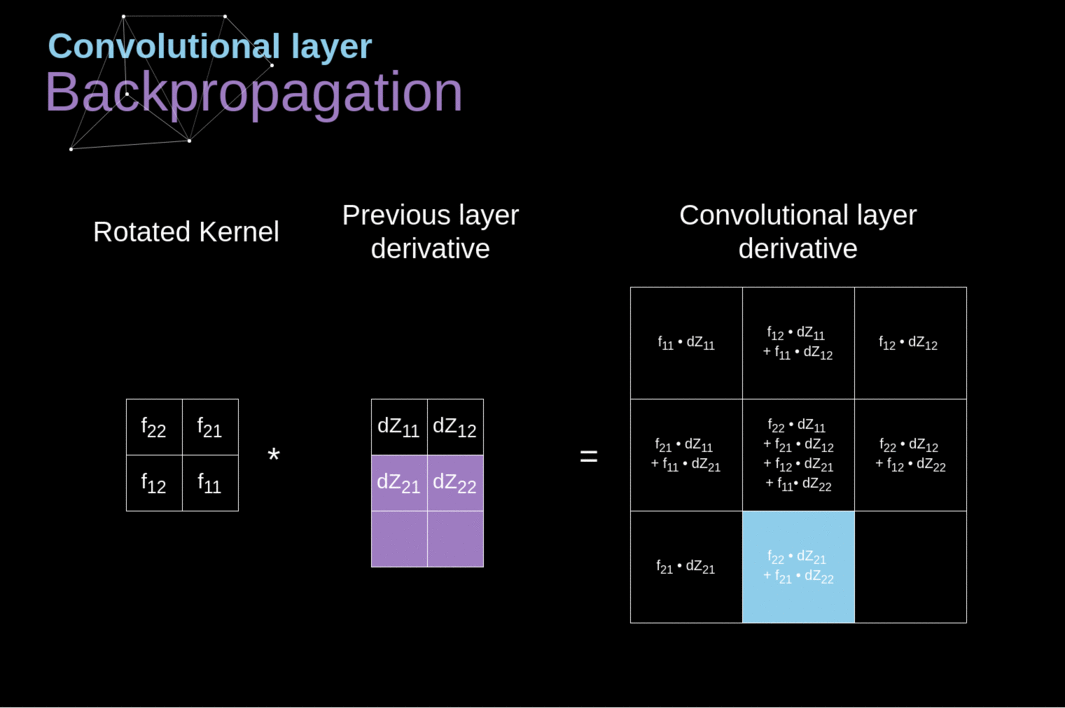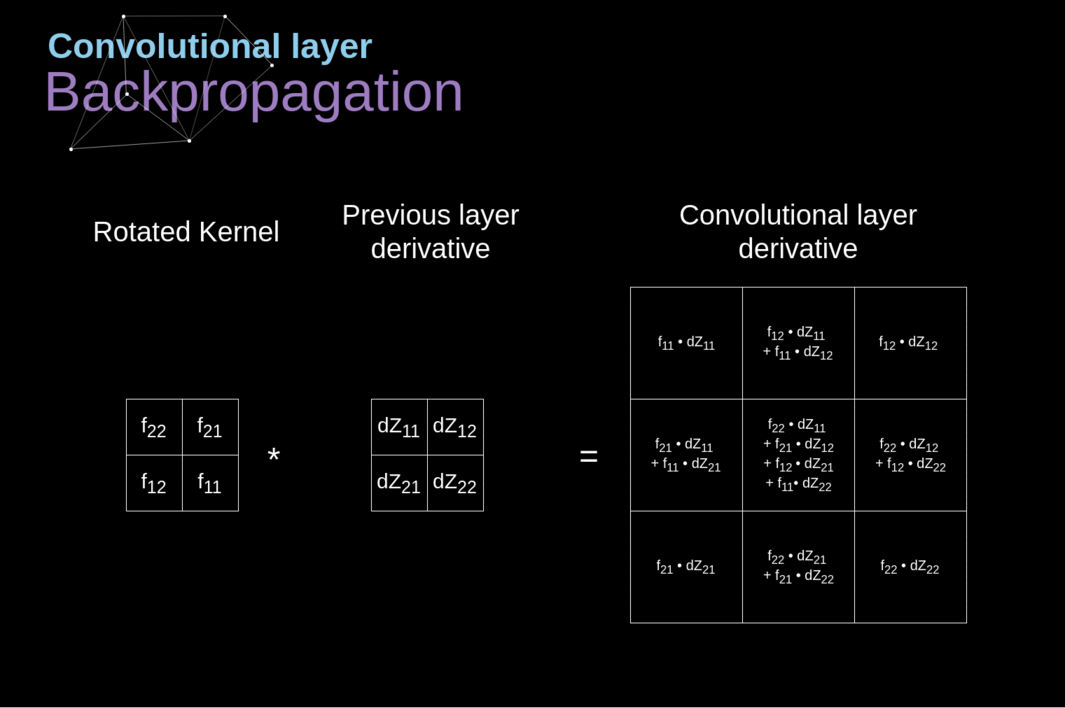
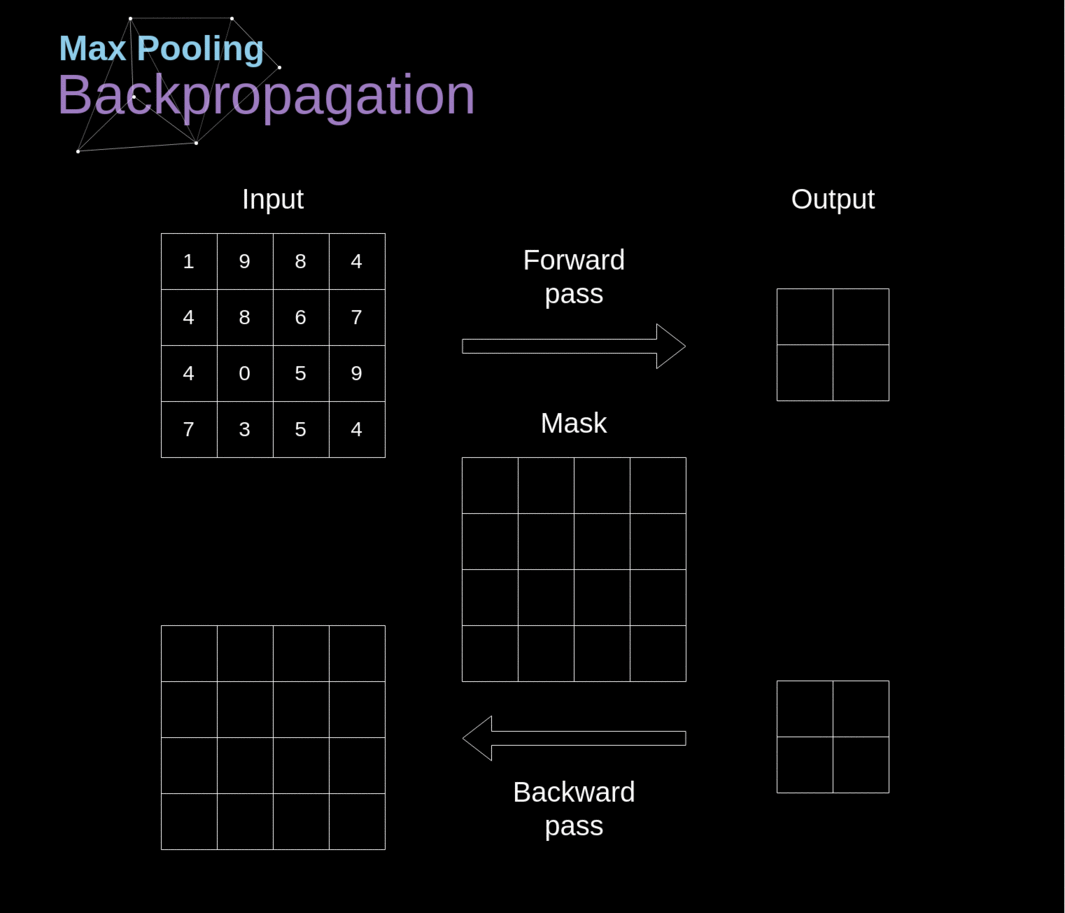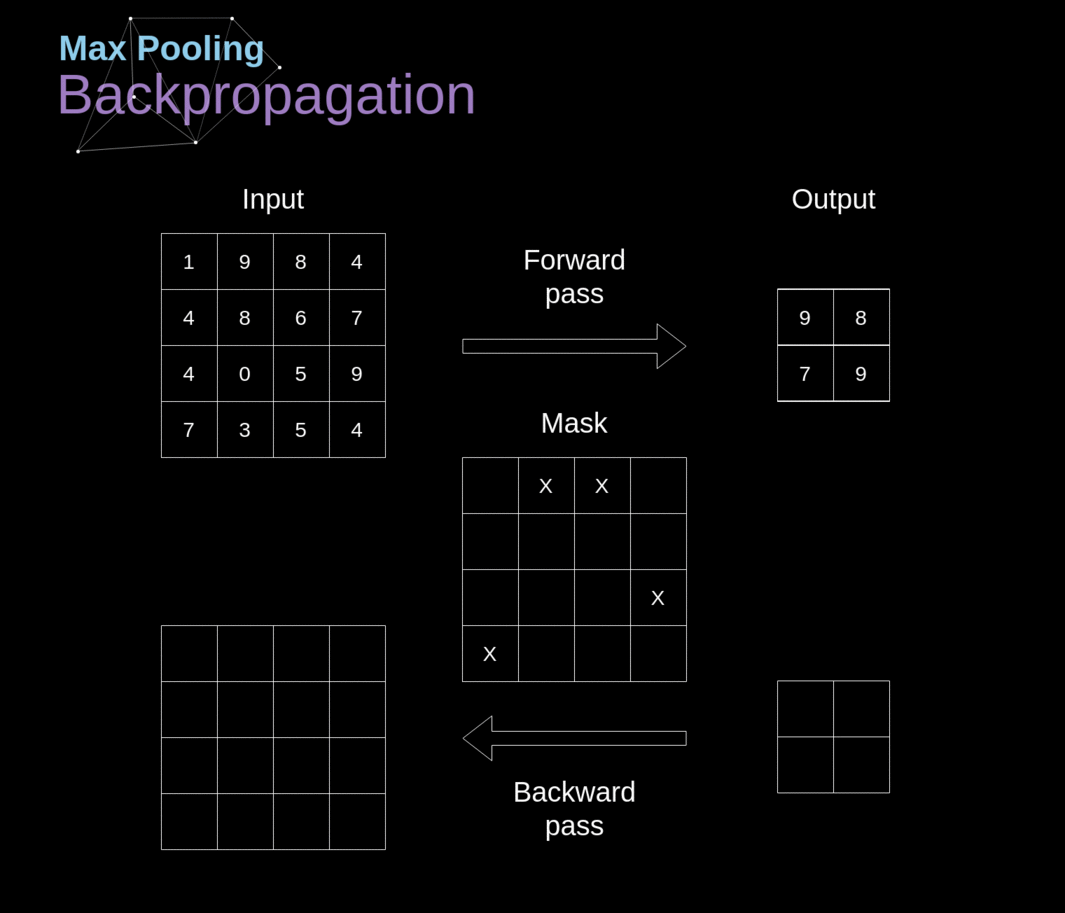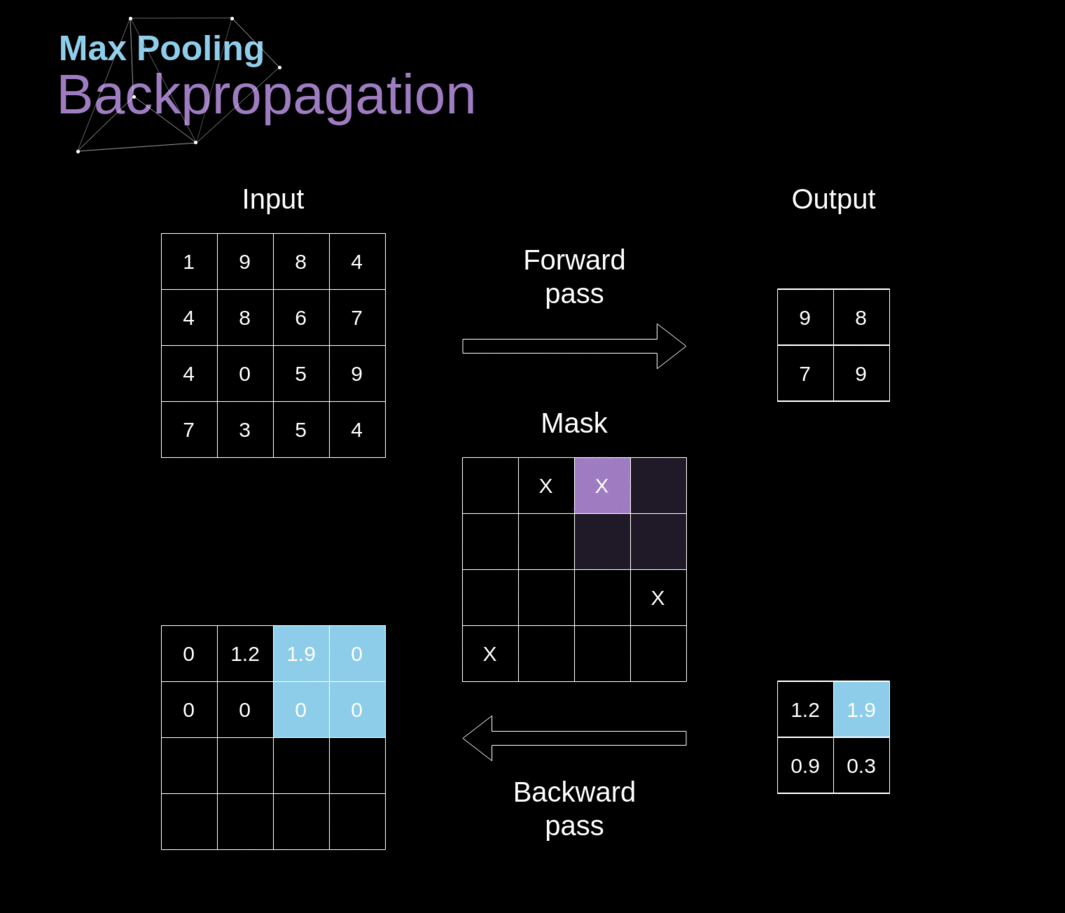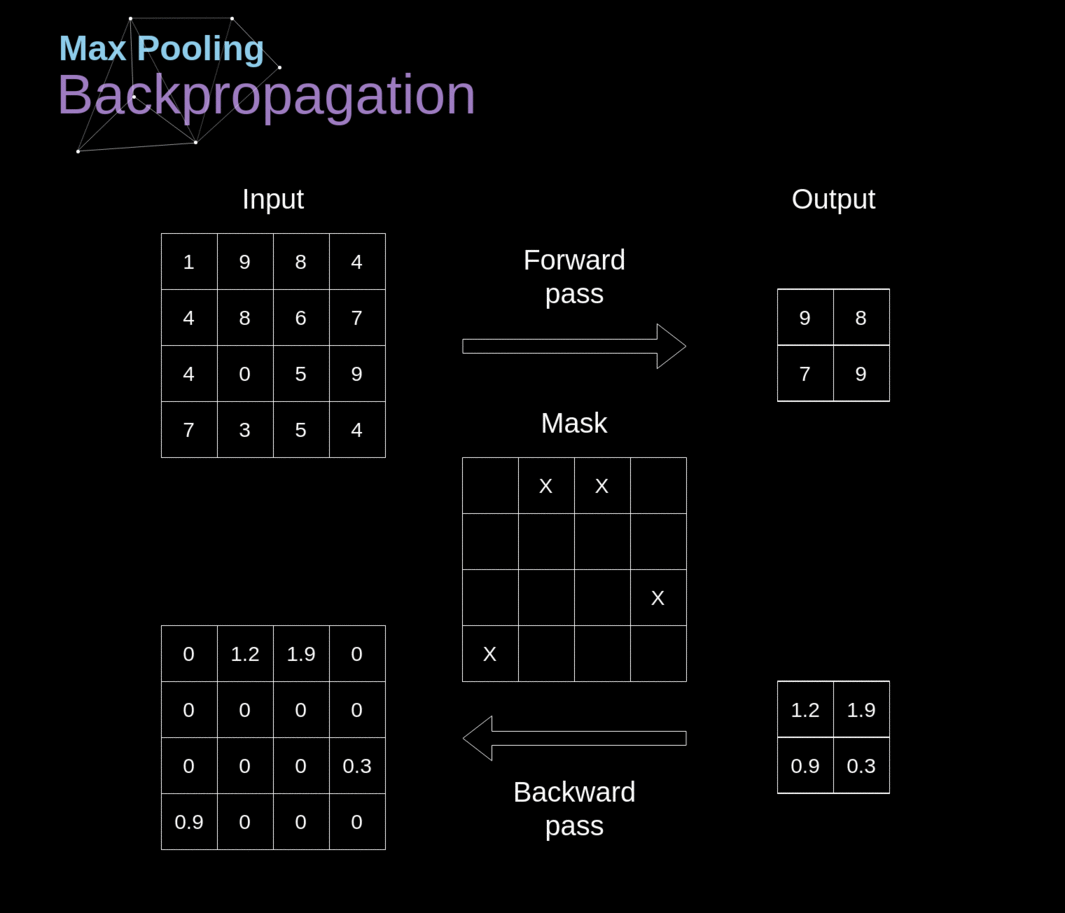
- O princípio é similar ao backpropagation em redes neurais completamente conectadas.
- Entretanto, deve-se levar em consideração os operadores de convolulção e pooling
- Identificar quais células participam de cada operação
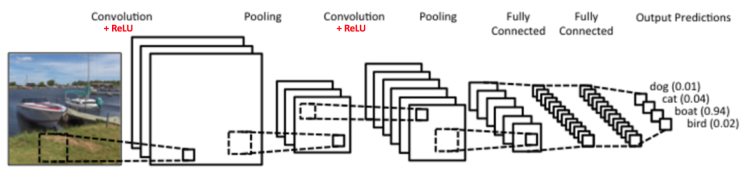
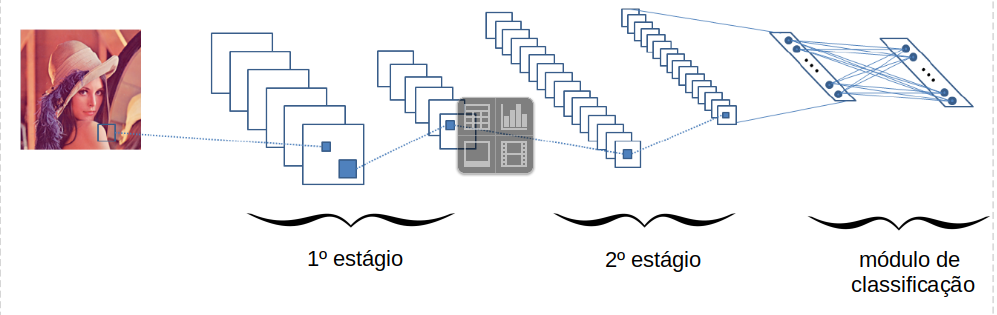
- Em uma CNN, encontramos um ou mais estágios, cada qual composto por camadas:
- de convolução (CONV),
- de subamostragem (POOL),
- outras...
- Ao final, é comum encontrar uma ou mais camadas completamente conectadas seguida de camada softmax (módulo de classificação).
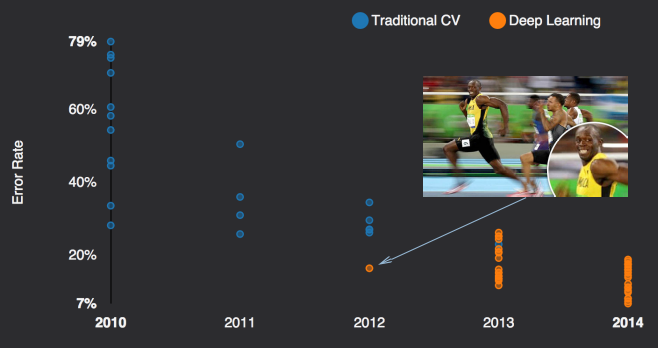
- Competição ILSVRC (ImageNet Challenge)
- ~1,2M de imagens de alta resolução para treinamento;
- ~1000 imagens por classe; 1000 classes!
- Ganhou a edição 2012
- Até então, soluções incluiam características produzidas manualmente, estudadas e melhoradas por décadas.