-
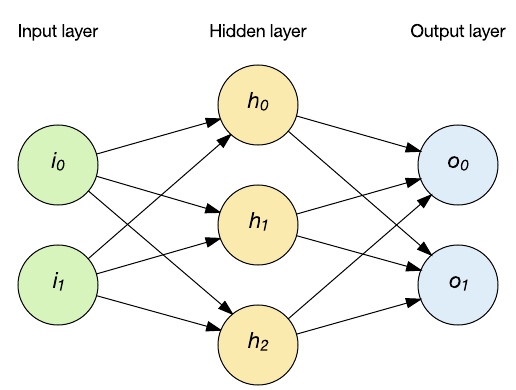
Constituem uma ampla classe de redes cuja evolução do estado depende tanto da entrada corrente quanto do estado atual.
-
São sistemas Turing-completos i.e., com tempo, dados e neurônios suficientes, RNNs podem aprender qualquer coisa que um computador pode fazer.
-
Aplicáveis a dados sequenciais
-
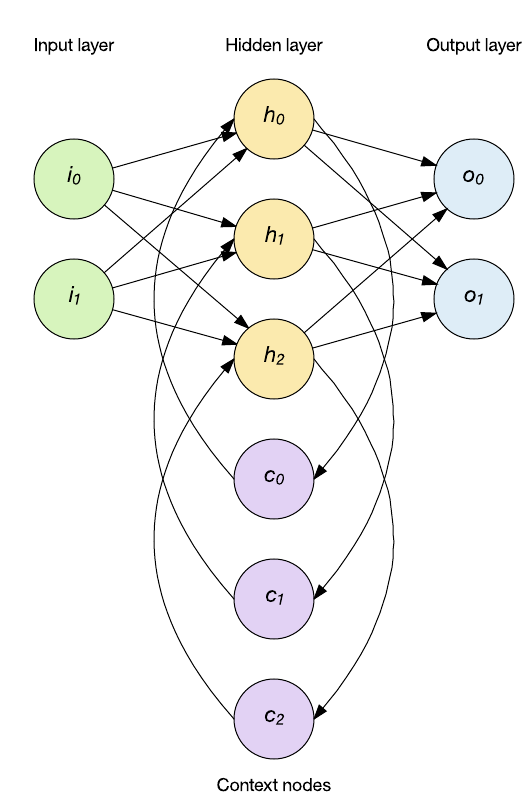
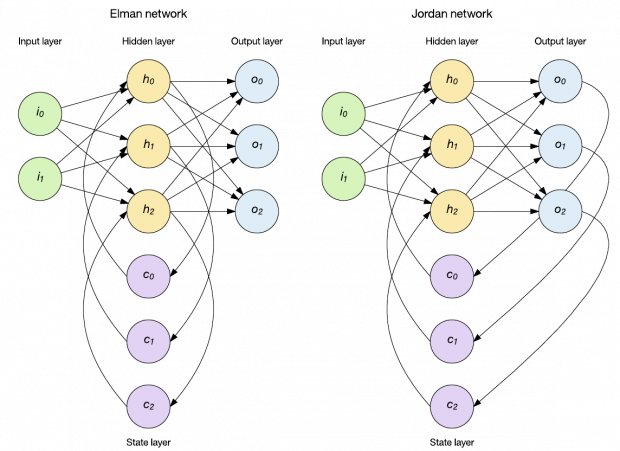
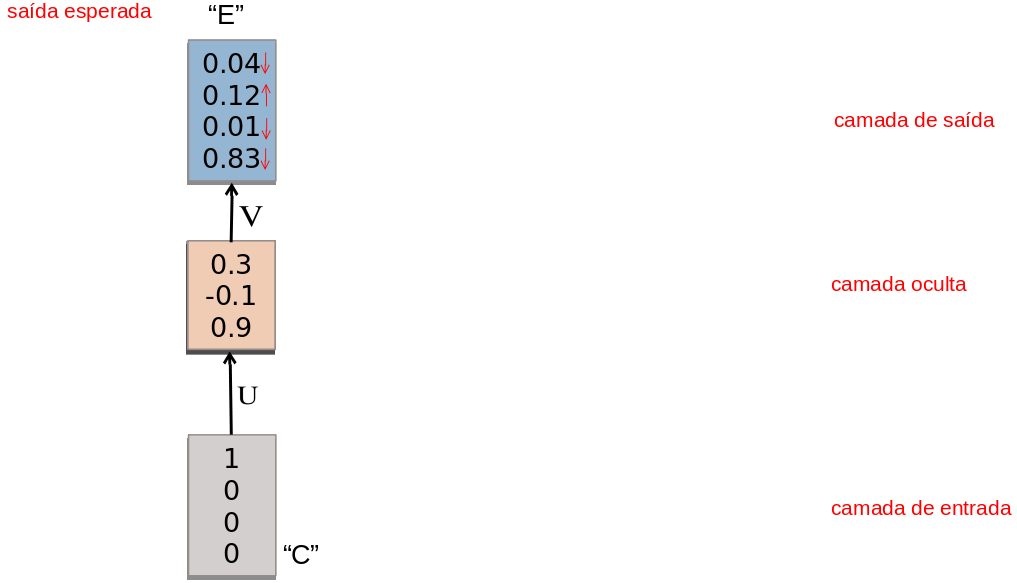
No caso da rede Elman, a camada oculta alimenta uma camada de estado de nodes de contexto que retém memória de entradas passadas.
-
As redes Jordan diferem em que, ao invés de manter o histórico da camada oculta, elas armazenam a camada de saída na camada de estado.
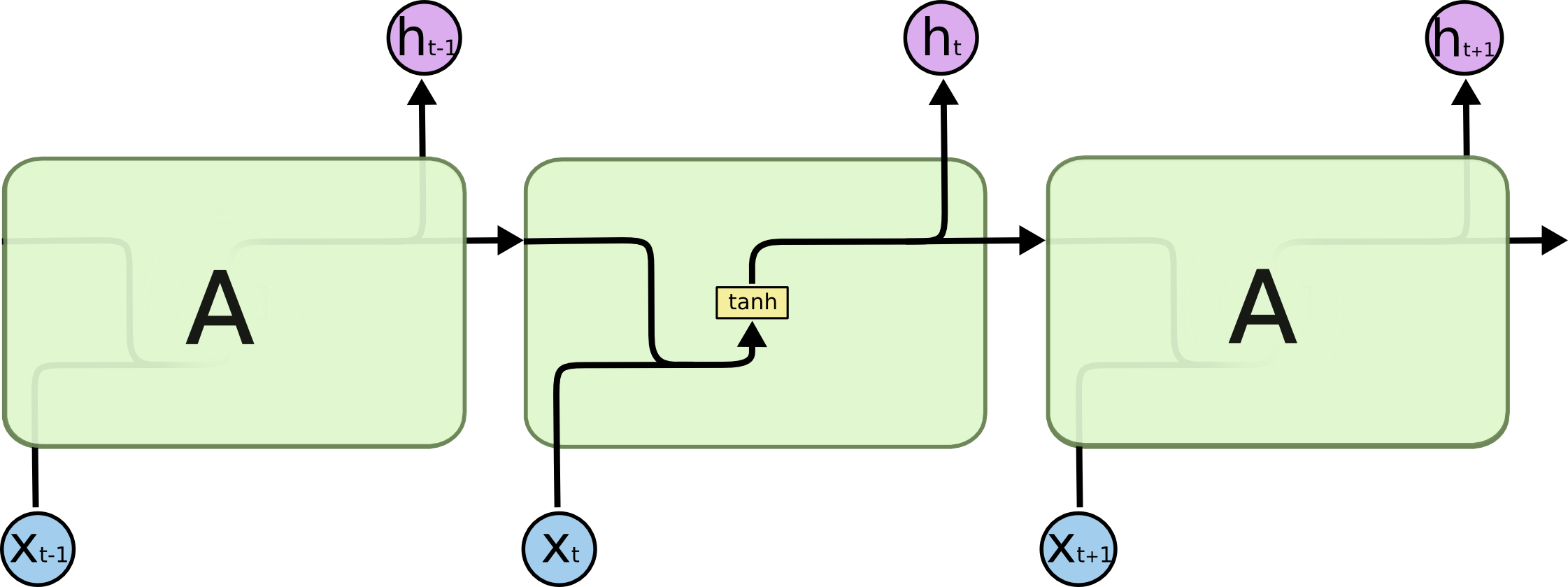
- Uma RNN mantém em sua(s) camada(s) oculta(s) uma memória interna dos dados que lhe foram apresentados.
- Essa memoria é uma combinação dos dados de entrada e do estado anterior da camada oculta.
- A rede aprende o que "relembrar"

- A rede aprende o que "relembrar"
-
Além disso, a rede as redes podem aprender a esquecer ou relembrar memórias relevantes
-
A entrada muda o que está na memória, e a saída é baseada na memória e saída.
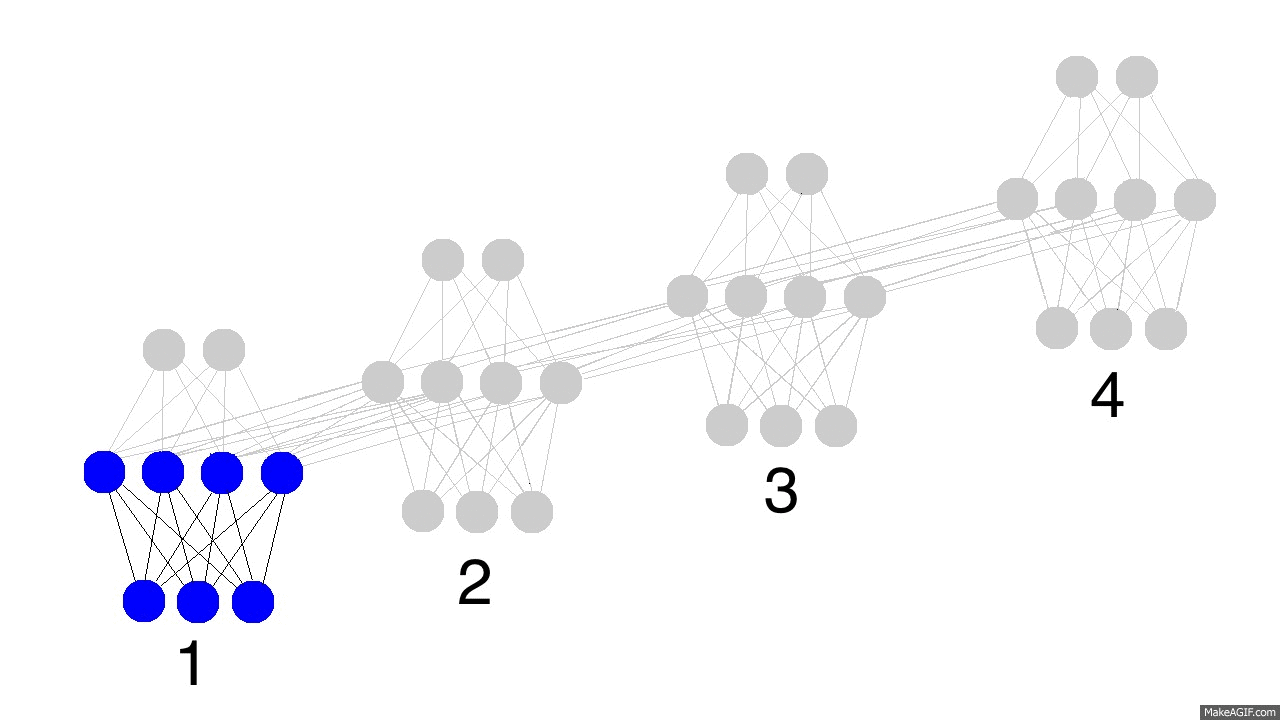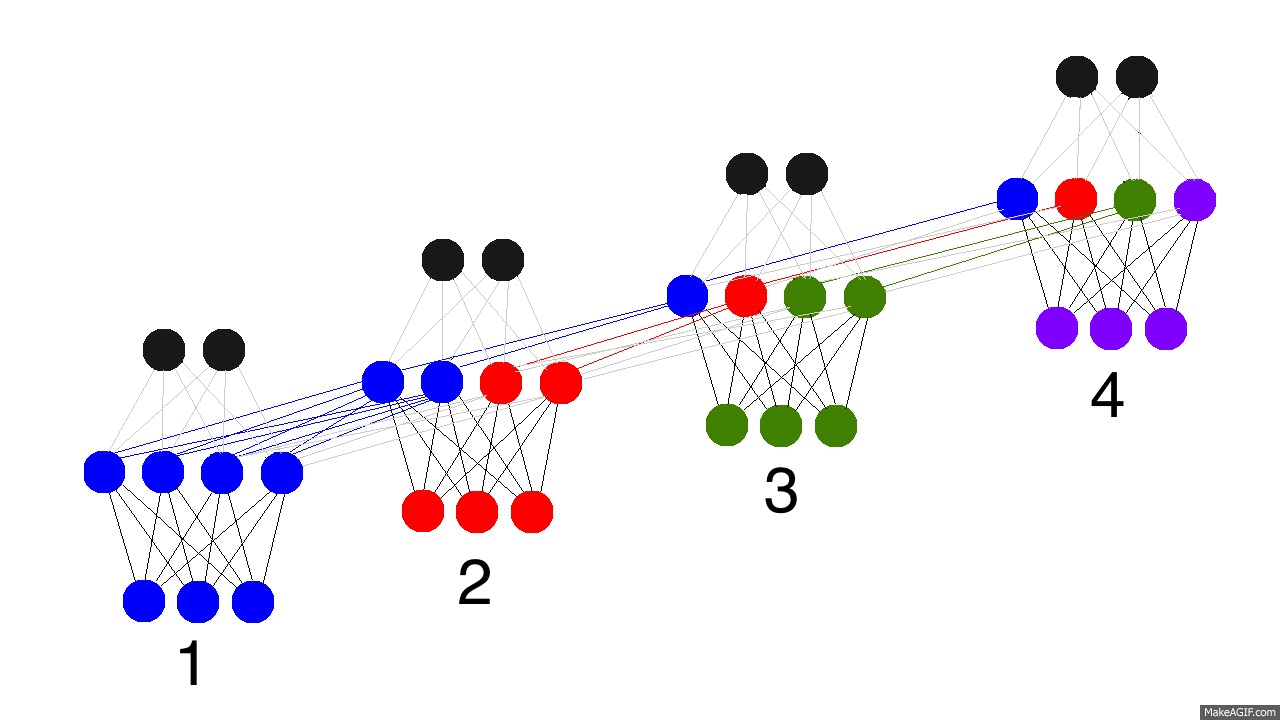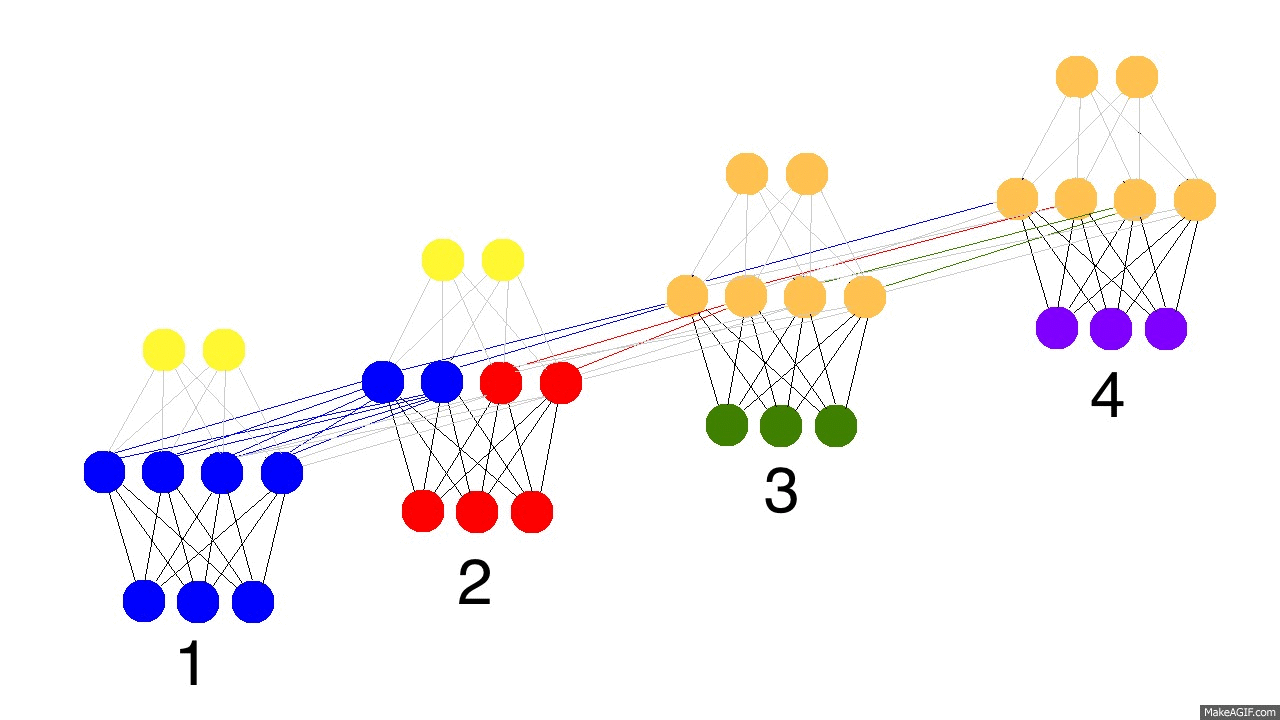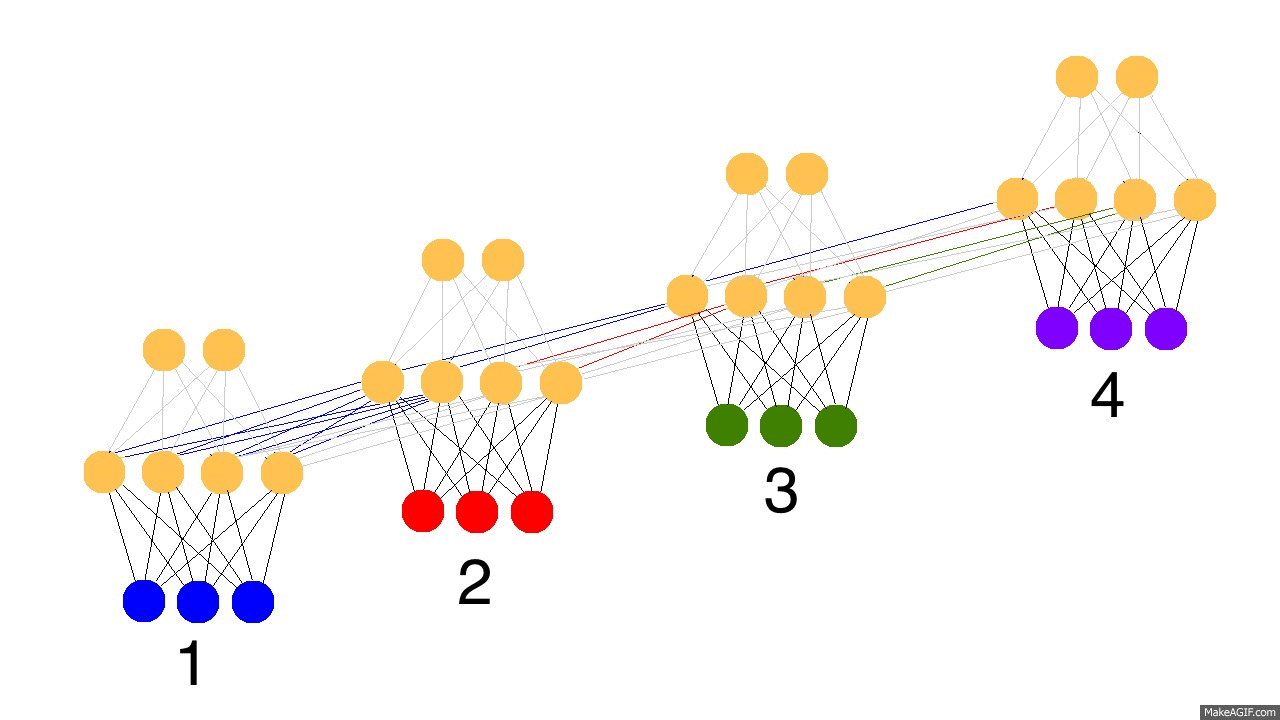
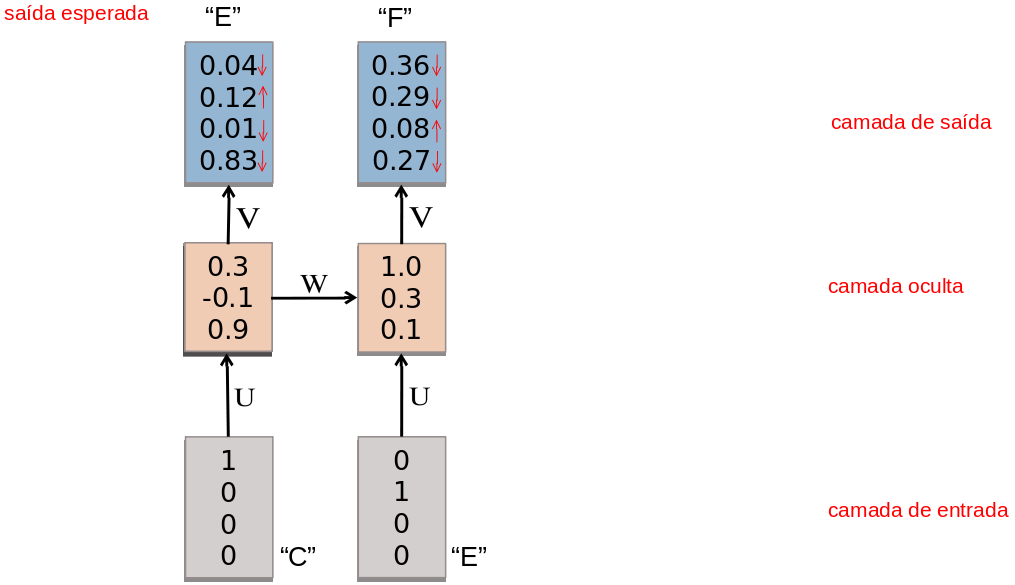
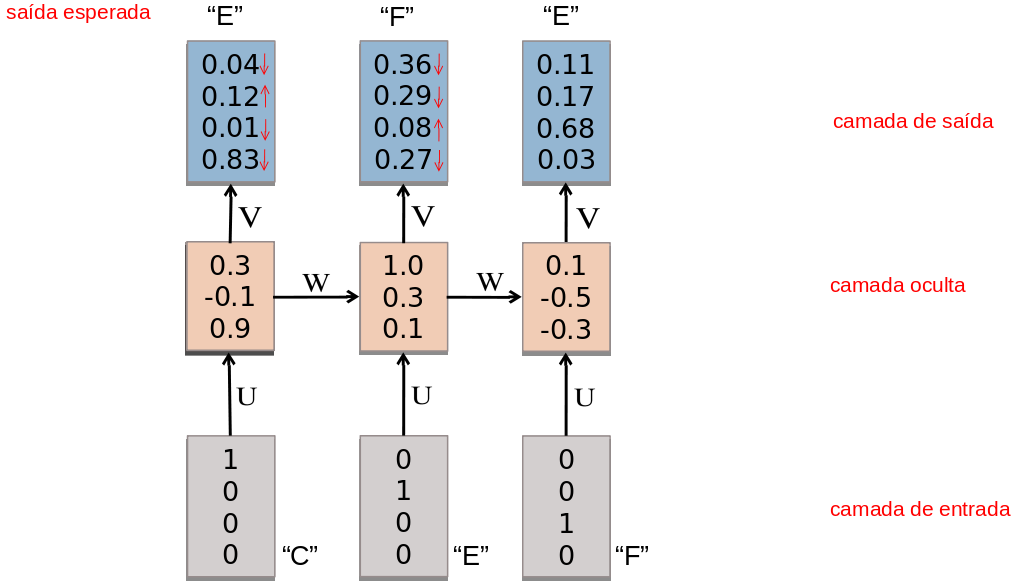
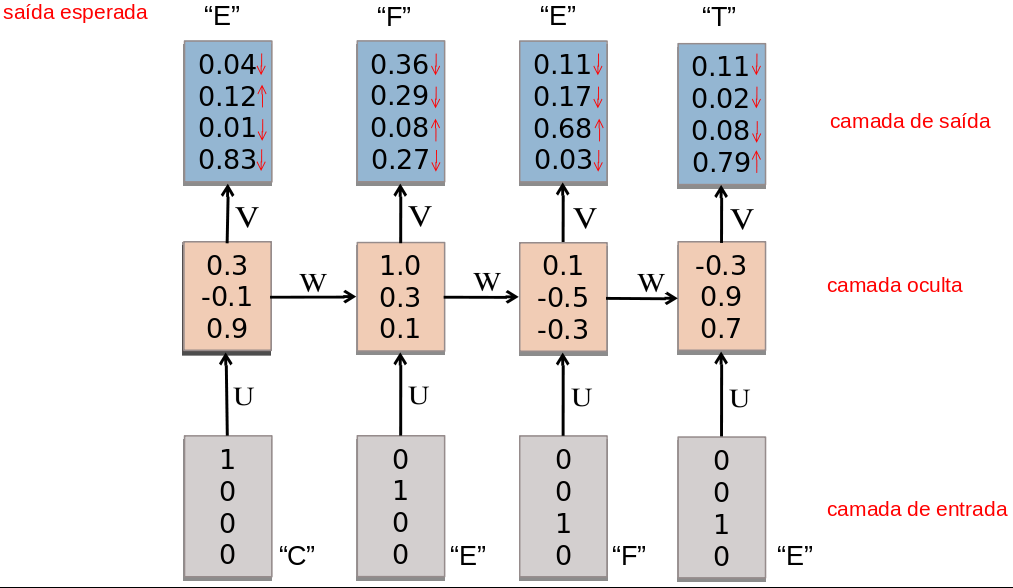
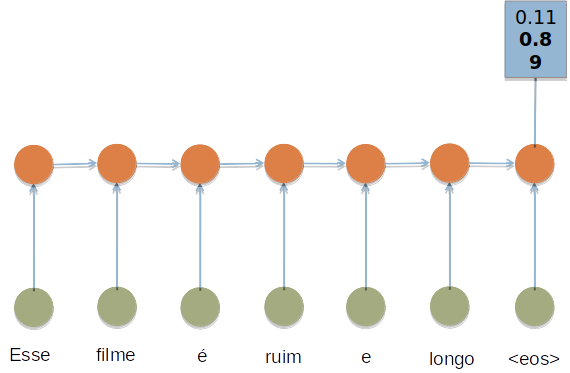
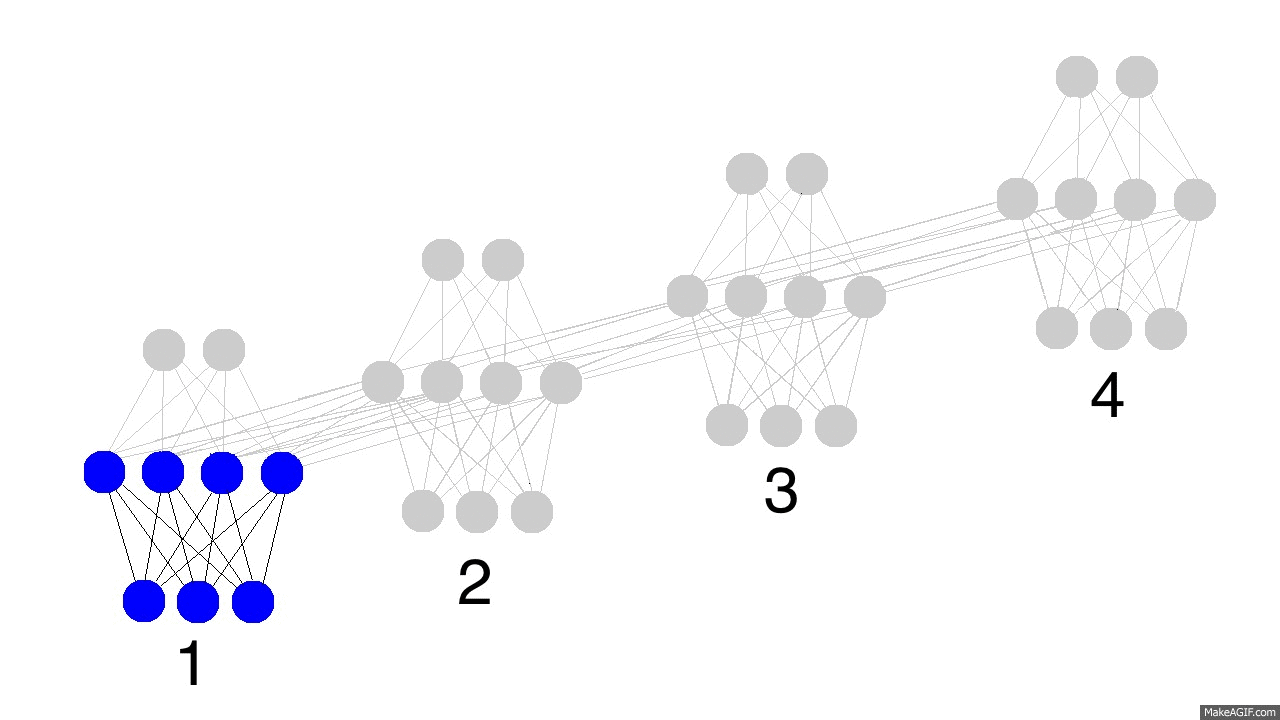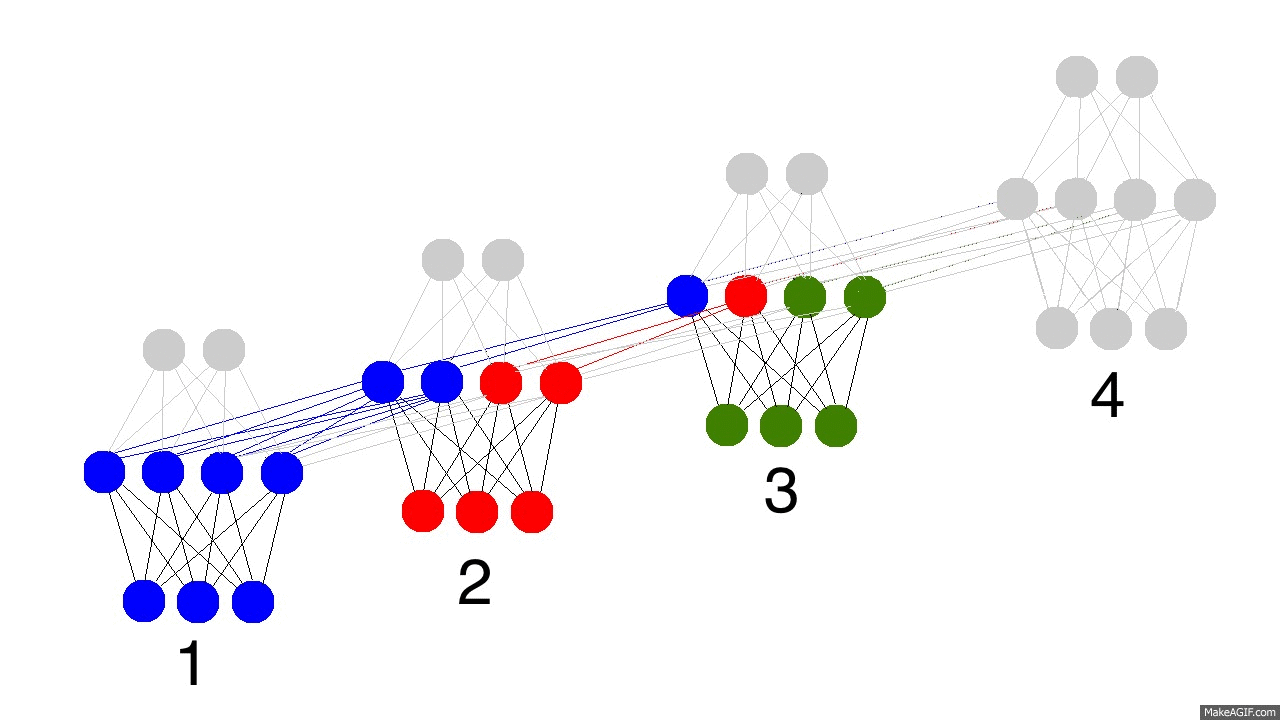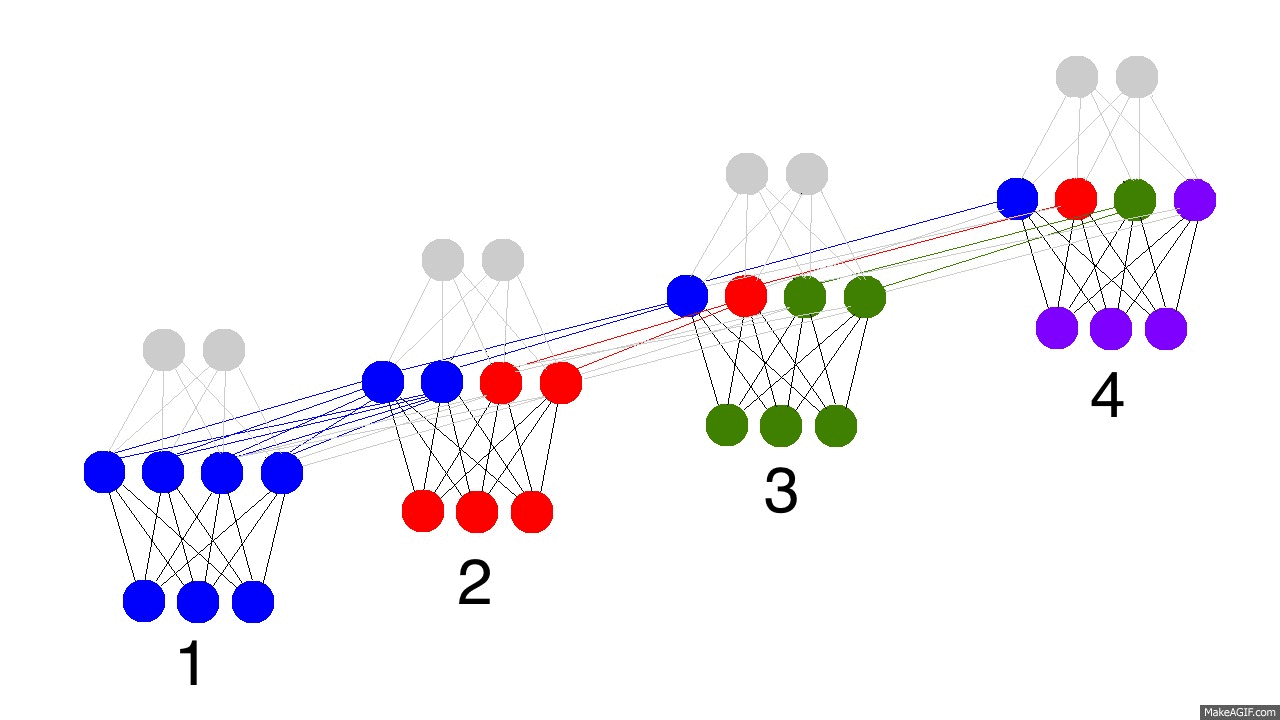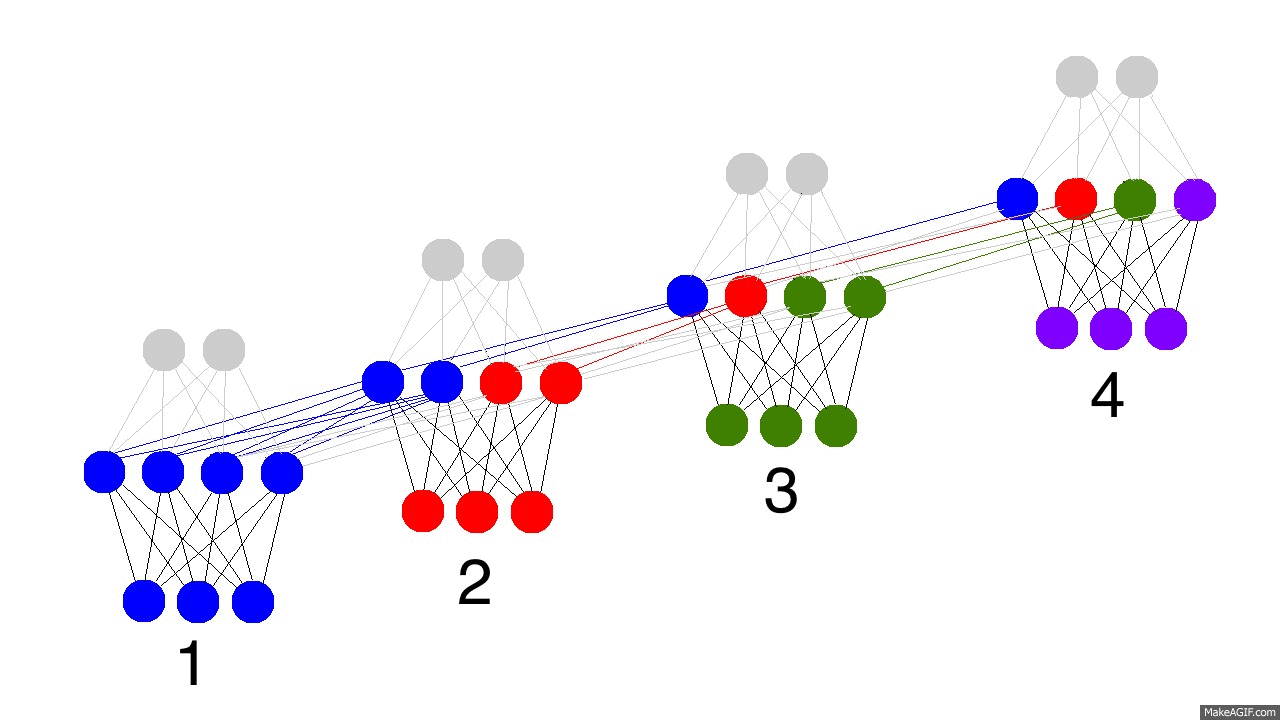
- RNNs são treinadas em uma sequência de sinais da entrada, um em cada passo de tempo.
- Uma RNN que recebe uma sequência de n vetores de entrada pode ser vista como uma rede alimentada adiante de n camadas.
- Matrizes de pesos são reusadas a cada passo de tempo (shared weigths).
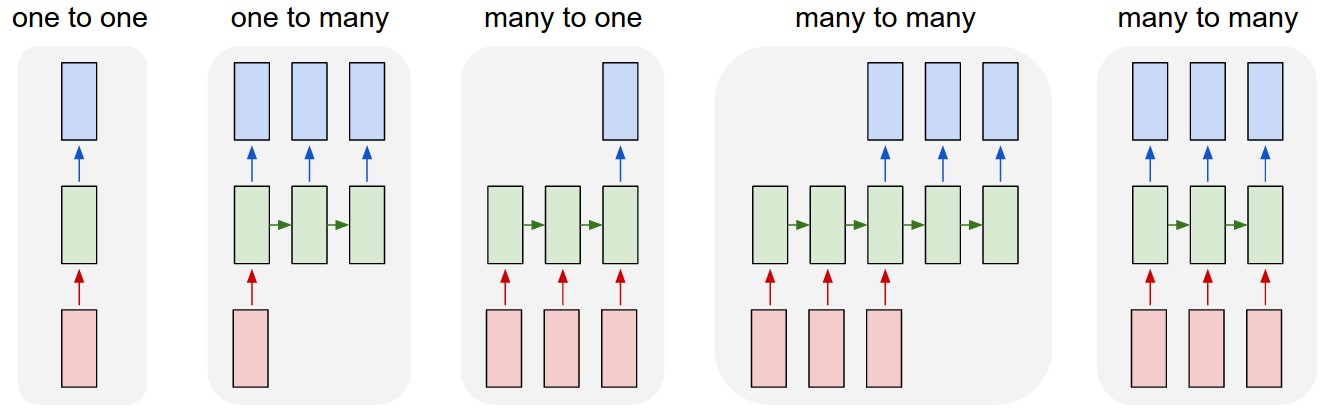
- Desdobramento no tempo permite o aprendizado de mapeamentos entre sequências de entrada e de saída com diferentes tamanhos:
- um-para-muitos,
- muitos-para-um,
- muitos-para-muitos.
- um-para-muitos
- prever a legenda correspondente a uma imagem.
- muitos-para-um
- prever a carga de sentimento (positiva ou negativa) de uma frase de entrada.
- muitos-para-muitos
- traduzir uma frase do inglês para o português
- rotular os quadros (frames) de um vídeo
- TTS (text-to-speech)
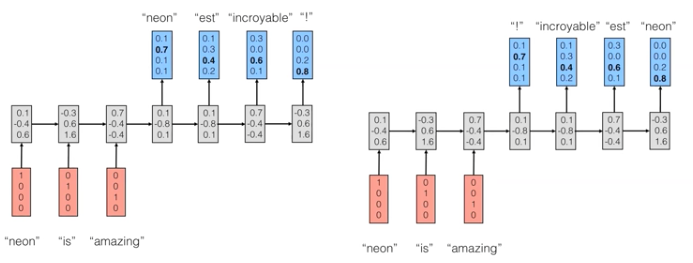
- Considere uma RNN que, a cada passo de tempo, prediz o próximo caractere de uma sequência, dada uma sequência de caracteres anteriores.
- Essa rede pode ser usada para gerar novos textos, um caractere por vez (character-level language model).
- Considere um RNN que, a cada passo de tempo, é alimentada com uma palavra.
- Ao final de uma sentença, prever qual é a carga de sentimento daquela sentença.
- Considere um RNN que, a cada passo de tempo, é alimentada com uma sentença.
- O objetivo é tentar predizer a tradução da sentença em uma outra língua.
- Variante do backprop para RNNs.
- Pode ser entendido ao interpretarmos uma RNN como a uma rede alimentada adiante na qual:
- há uma camada para cada passo de tempo;
- a matriz de pesos de cada camada é a mesma (i.e., há o compartilhamento de pesos).
- Por exemplo, considere que w1 e w2 são pesos de conexões correspondentes na camada oculta em instantes de tempo distintos.
- o BPTT calcula os gradientes relativos a ∂w1∂J e ∂w2∂J e usa a média dessas quantidades para atualizar w1 e w2.
- Dois problemas que podem ocorrer durante o treinamento de RNNs:
- Vanishing gradients
- Exploding gradients
- Uma das causas: o fluxo de informação (propagação dos gradientes) em uma RNN ocorre por meio de sequências de multiplicações.
- Vanishing: Os gradientes “desaparecem” (i.e., tendem a zero) quando são continuamente multiplicados por números inferiores a um.
- Exploding: Os gradientes se tornam exponencialmente grandes quando são multiplicados por números maiores que 1.
- Algumas técnicas para atenuar o problema da explosão dos gradientes:
- Truncar o BPTT (truncated BPTT)
- Truncar os gradientes (gradient clipping)
- Usar otimizadores que ajustem adaptativamente a taxa de aprendizado (os pacotes com keras, tensorflow, etc, implementam vários).
- Corresponde a limitar a quantidade de passos de tempo no passo backward a um valor máximo preestabelecido.
- e.g., aplicar backprop a cada 10 passos.
- Desvantagem: perda do contexto temporal.
- Se o comprimento do vetor gradiente ultrapassar um valor máximo preestabelecido, truncar.
- Várias possibilidades...uma delas:
- new_gradients = gradients * threshold / l2_norm(gradients)
- Técnica simples e efetiva!
- Muito mais difícil de detectar!
- Alternativas de solução:
- Usar boas estratégias de inicialização dos pesos
- Usar otimizadores que adaptam a taxa de aprendizado (os pacotes como keras, tensorflow, etc, implementam vários).
- Usar LSTMs ou GRUs
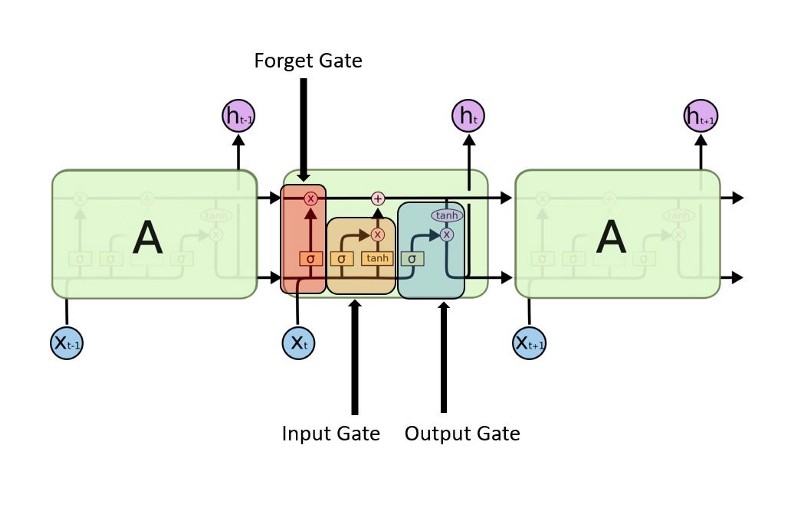
- Tipo de RNN que possui uma dinâmica de propagação de gradientes mais rebuscada.
- Adequada quando há intervalos muito longos de tamanho desconhecido entre eventos importantes.
- Durante o treinamento, uma rede LSTM pode aprender quando deve manter ou descartar informações.
- Em um vídeo (filme):
- quando termina uma cena, podemos esquecer o dia em que ela ocorreu;
- mas se um personagem morre na cena, devemos lembrar disso para entender as próximas.
- Em um texto, quando termina uma frase, um tradutor pode esquecer o gênero do sujeito.
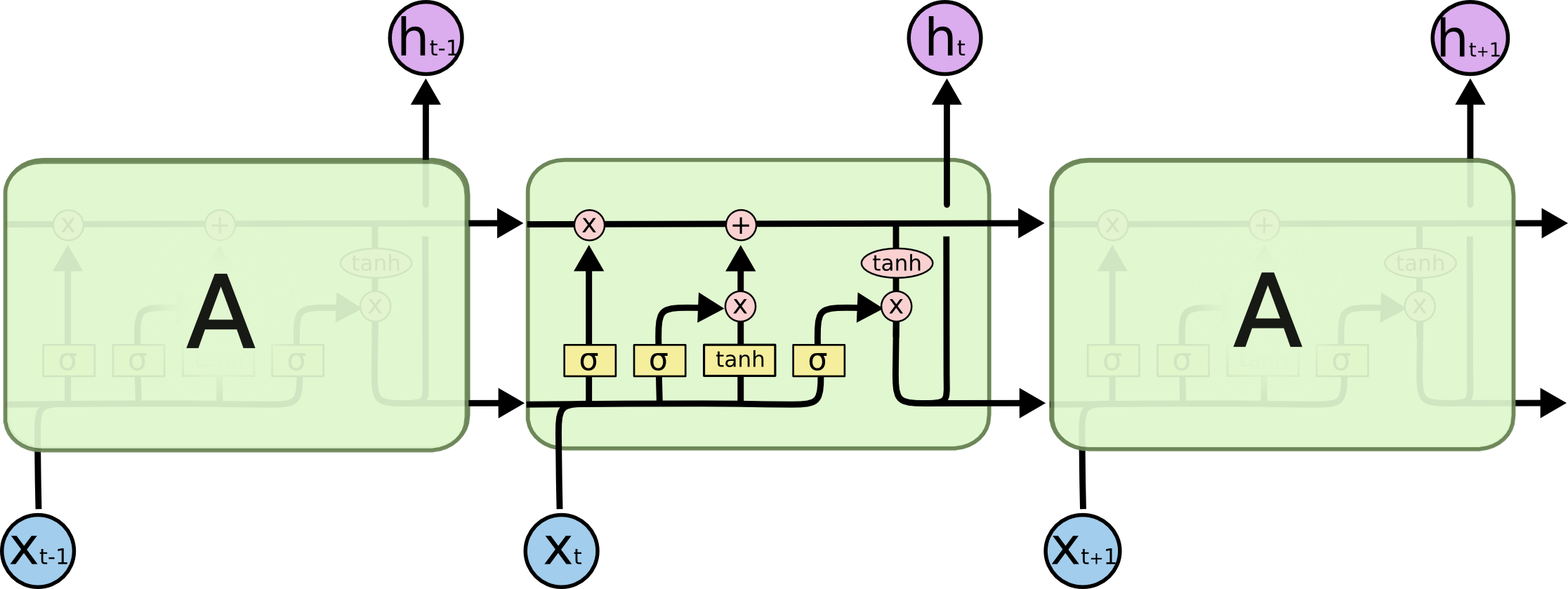
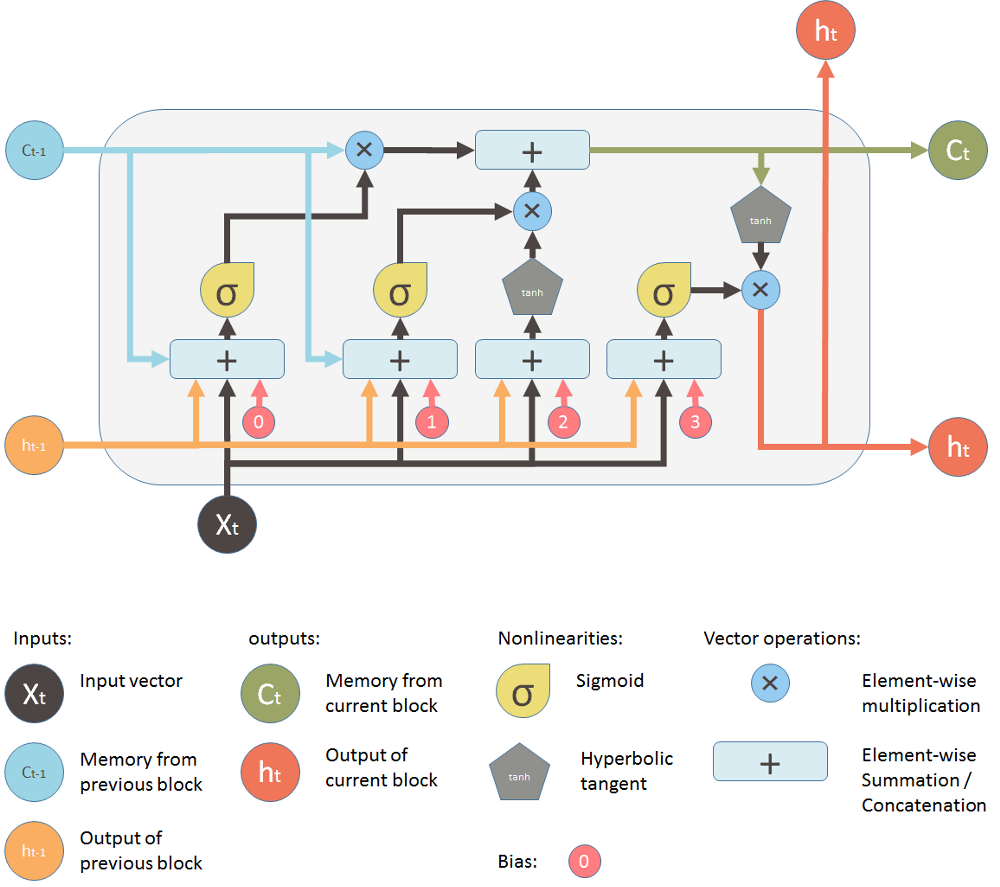
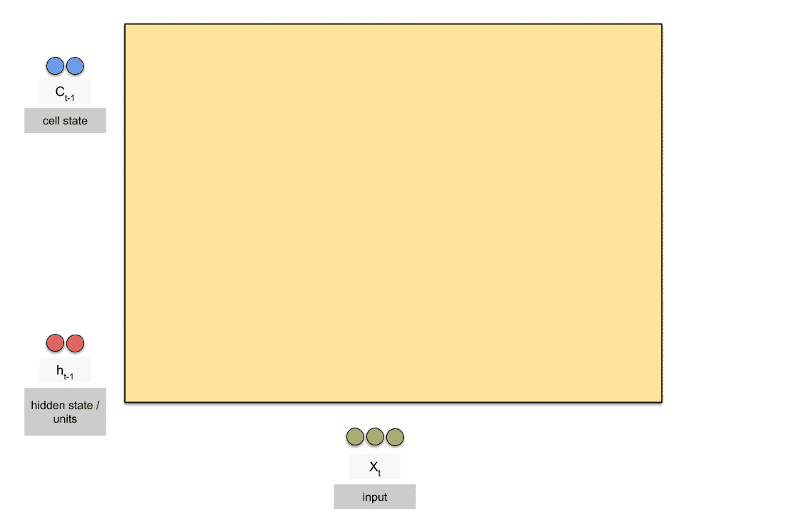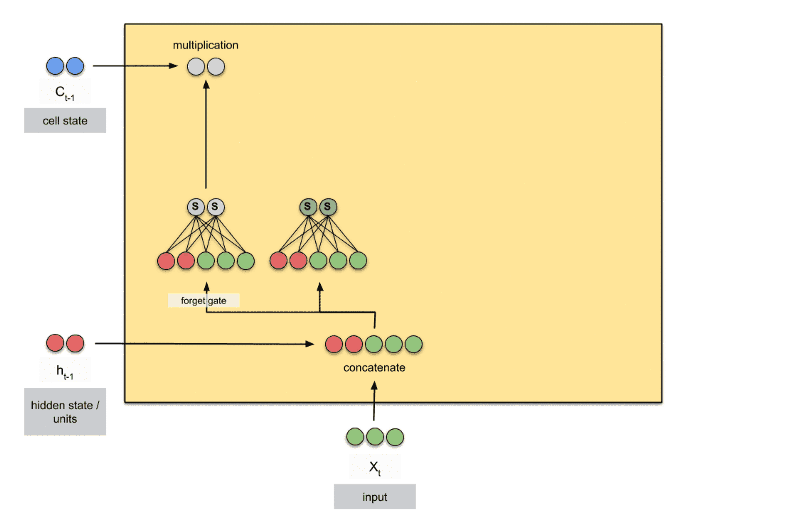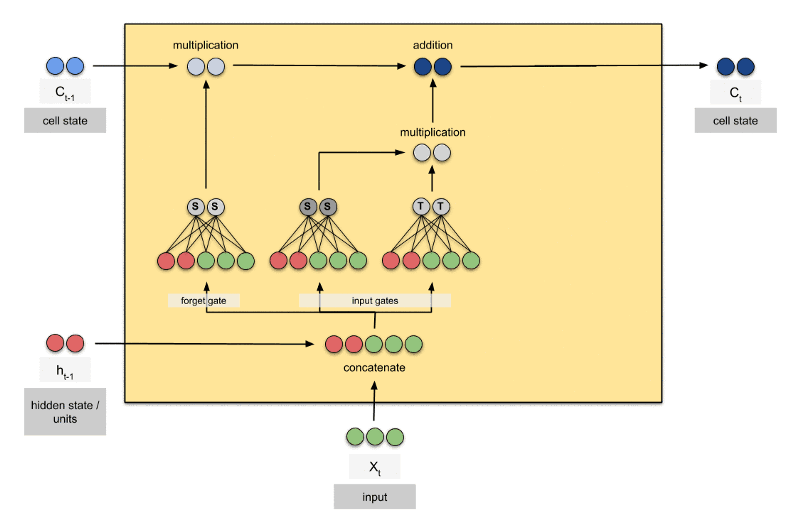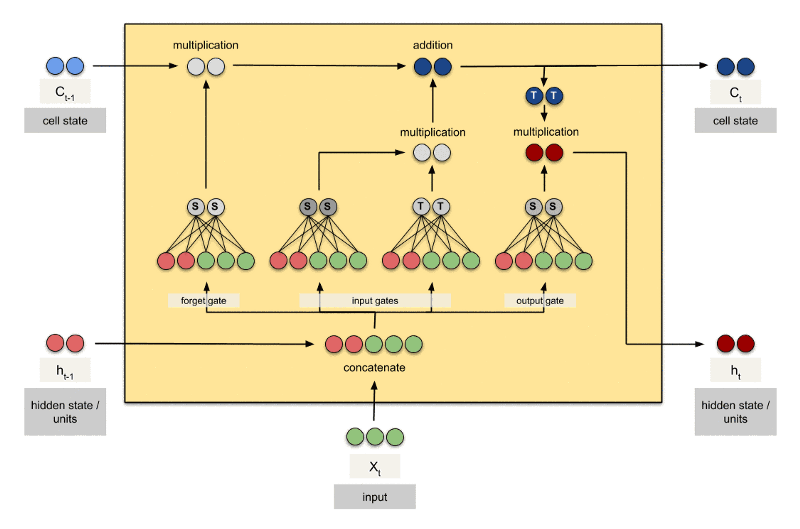
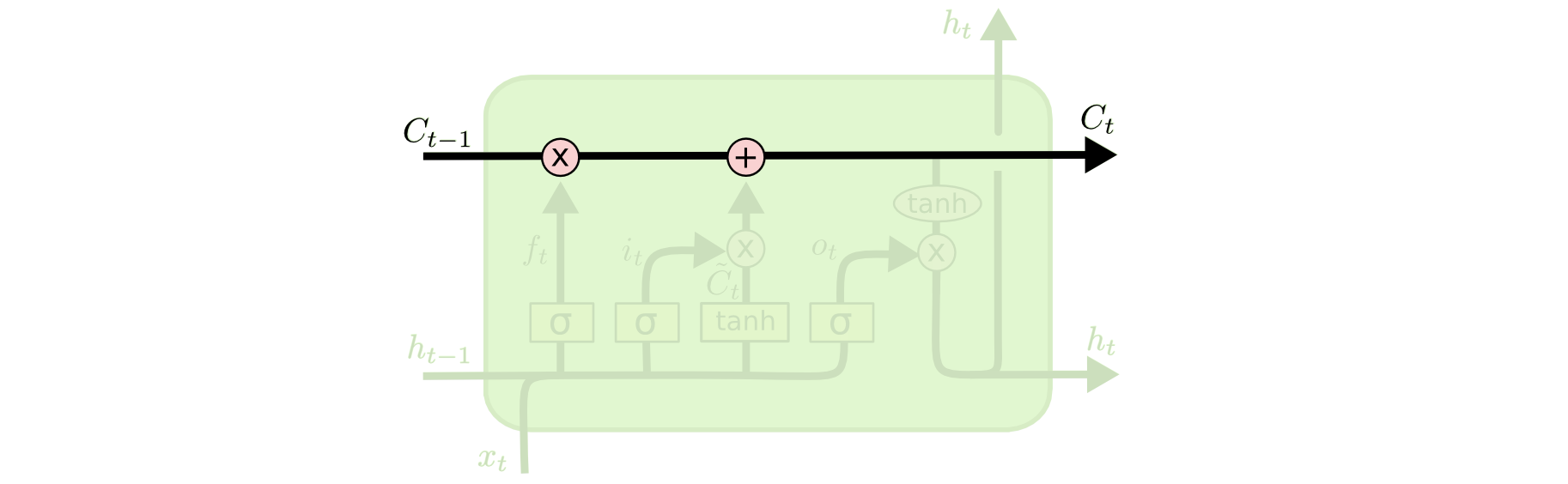
Há três portais em um bloco LSTM:
- forget gate
- memory gate (input gate)
- output gate
- O estado interno (h) carrega a informação sobre o que uma célula (C) leu ao longo do tempo.
- Essa informação pode ser usada no tempo presente, de modo que uma função de custo não dependa apenas dos dados que está vendo neste instante, mas também dados vistos anteriormente.
- O "tubo" superior é o tubo de memória, cuja entrada é a memória antiga Ct−1 (um vetor).
- A conexão que se liga por baixo é ft, o vetor resultante do portal esquecer (forget gate).
load_elastic_tensor
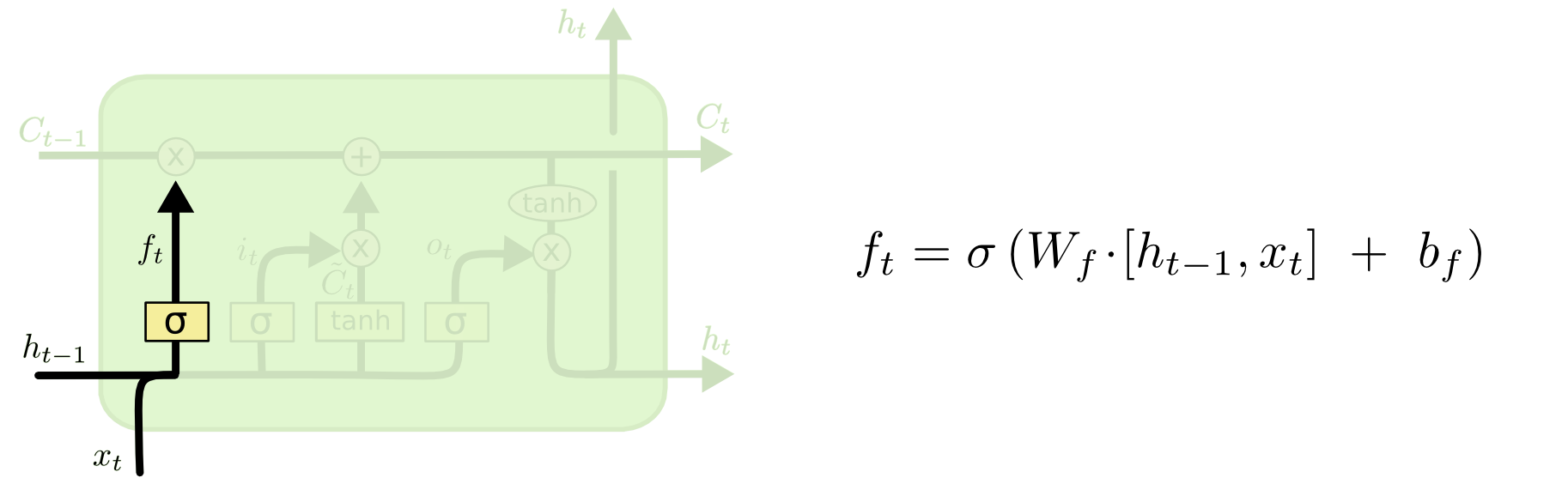
- Se Ct−1 for multiplicado por um vetor ft cujas componentes são próximas de
- 0, isso significa que a RNN quer esquecer a maior parte da memória antiga.
- 1, isso significa que a RNN deixa a memória antiga passar.
- A segunda operação aplicada ao fluxo de memória é uma soma.
- A soma mescla as memórias antiga e nova.
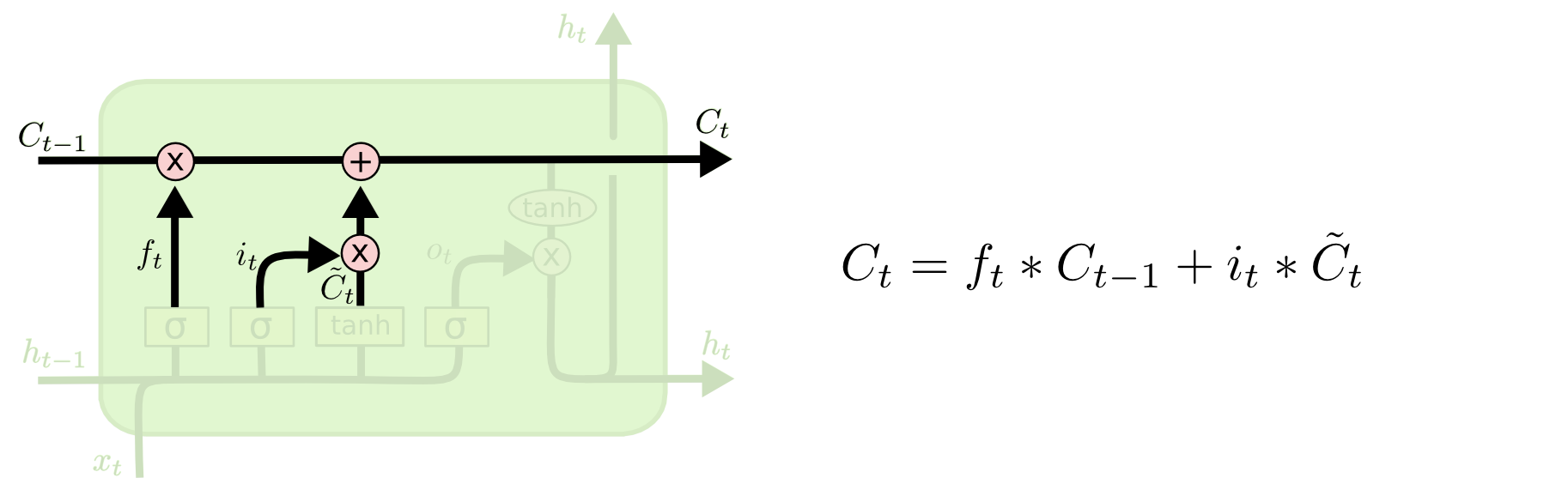
- A válvula abaixo da soma controla o quanto a nova memória deve ser mesclada com a antiga.
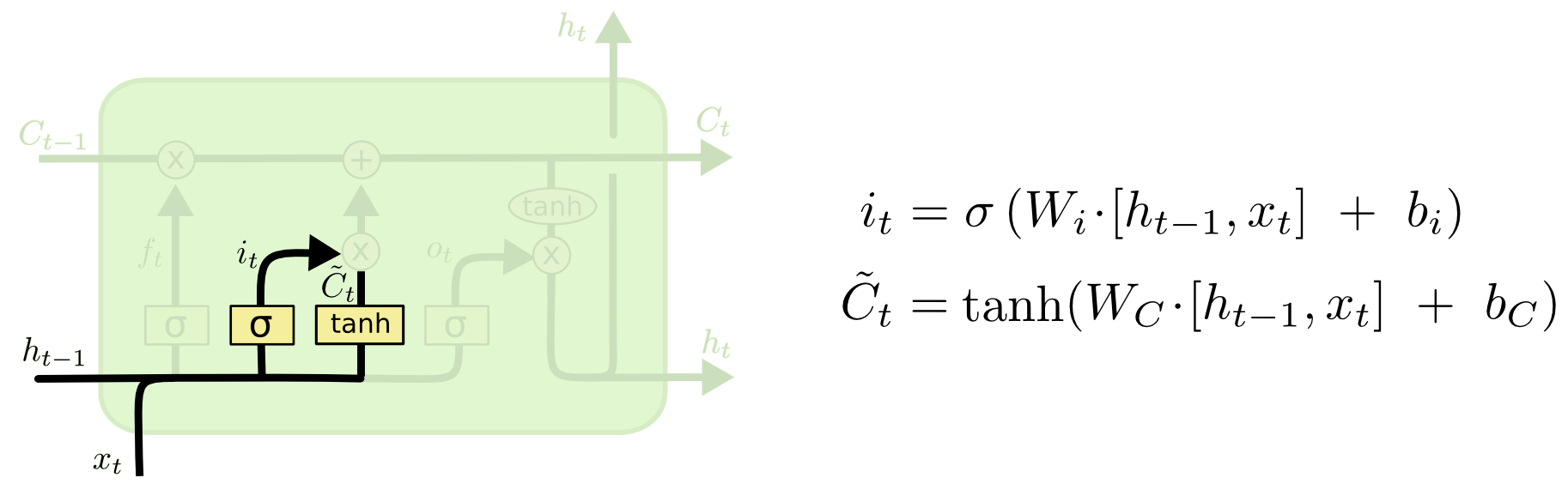
- Esse portal controla o quanto a nova memória influencia a memória anterior.
- Permite adicionar informação à memória da célula.
- A RNA desse portal recebe as mesmas entradas que as do forget gate.
- A última porta ht, a saída para o bloco LSTM.
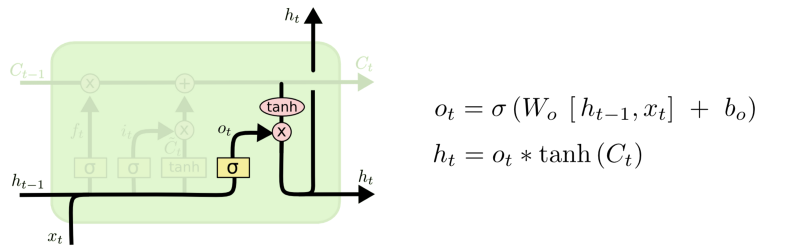
- Este passo possui uma válvula de saída que é controlada pelos seguintes componentes:
- nova memória,
- saída anterior $h_{t-1},
- entrada Xt,
- vetor bias.
- RNNs clássicas sobrescrevem o estado interno.
- LSTMs adicionam ao estado interno.
- Unidades LSTM proveem à RNN células de memória, que possuem operações para manipular a memória:
- leitura,
- gravação e
- reinicialização.
- Geff Hinton sobre o artigo que propôs as LSTMs:
if you can understant the paper, you are better than many people in machine learning. It took 10 years until people understand what they were talkink about”.
- Geração de rótulos para imagens