Classificação
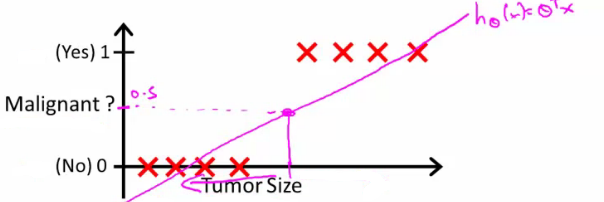
- Podemos usar regressão linear?
- pode ser representado como ou :
- : classe negativa
- : classe positiva
- Um ponto de corte no valor predito (p.ex. acima de 0.5), é classificado como classe positiva
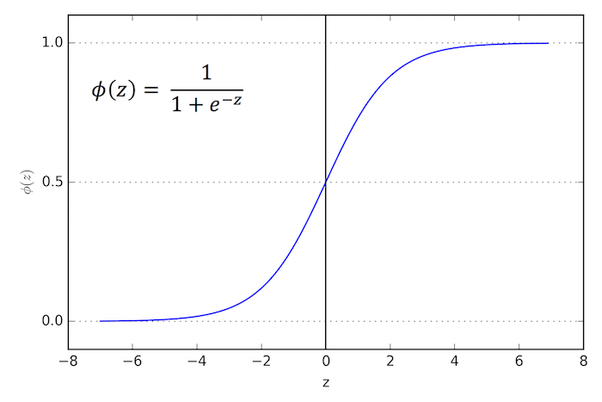
Regressão logística
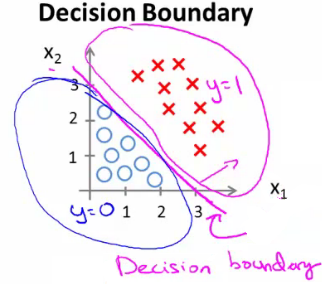
Fronteira de decisão
- A linha em que (ou que ) é a fronteira de decisão.
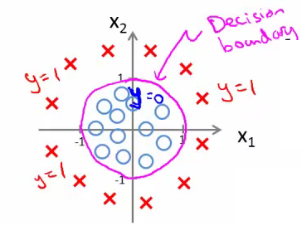
Fronteira de decisão não linear
-
Se adicionarmos novos atributos que fazem uma transformação não linear nos dados (como na aula passada, em que fizemos regressão polinomial adicionando atributos do tipo )
-
Por exemplo, se adicionarmos atributos quadráticos, podemos ter fronteiras de decisão do tipo
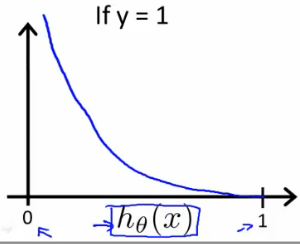
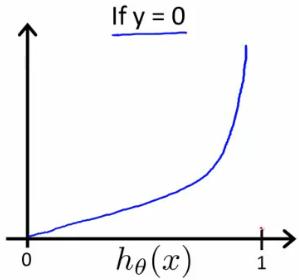
função de custo para regressão logística
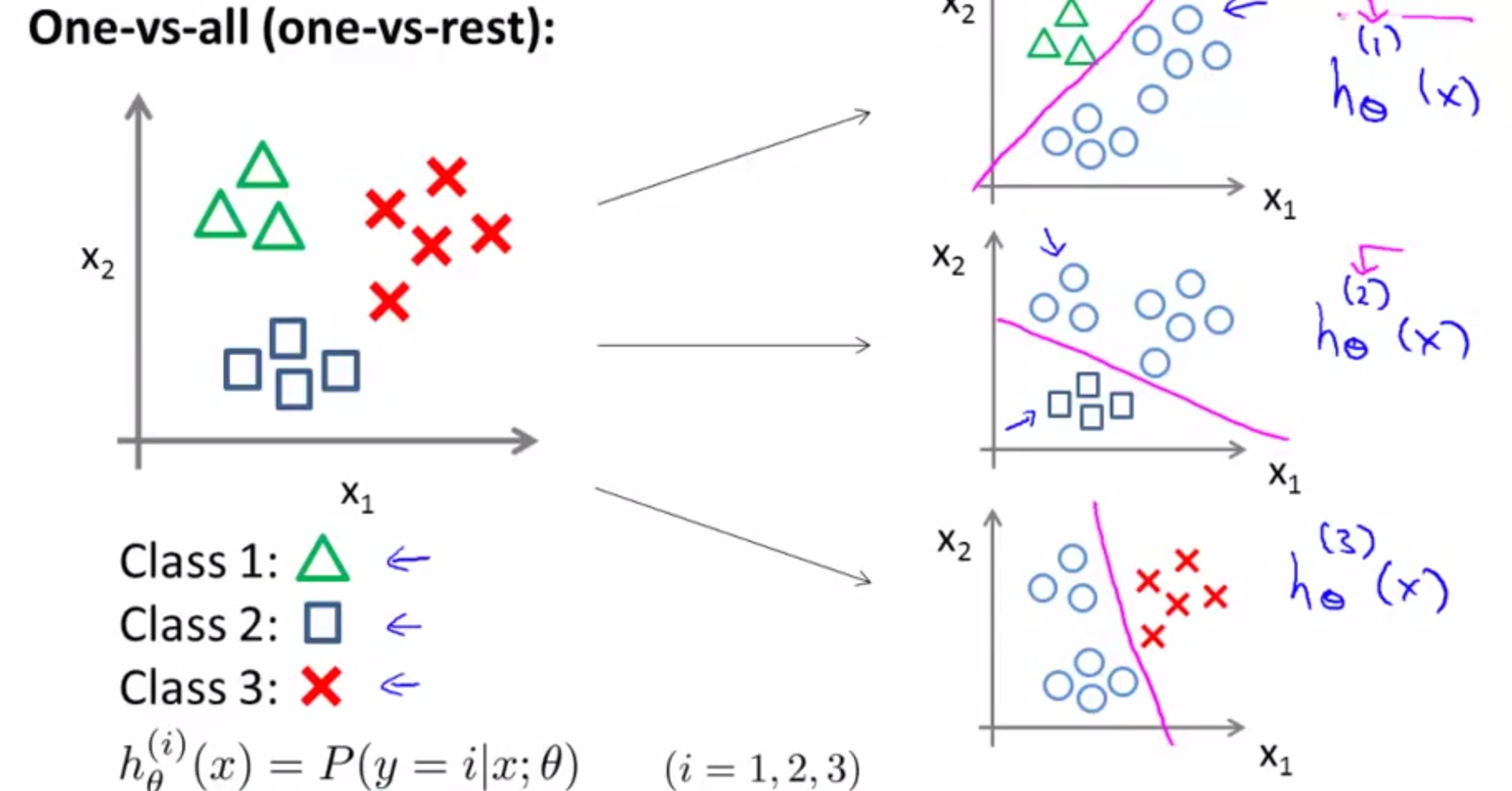
Regressão logística multiclasse
- Poblemas multiclasse: mais de duas classes
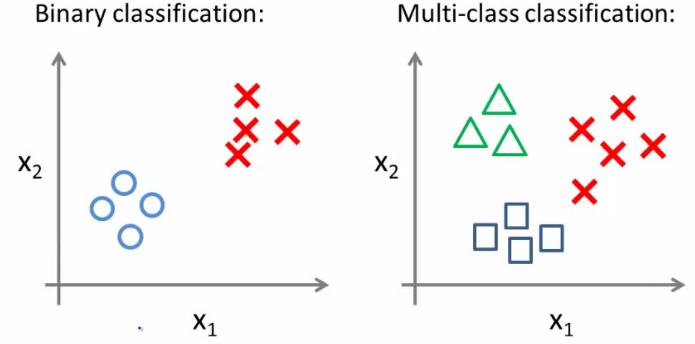
Regressão logística multiclasse