- Suponha que tenhamos um problema de classificação complexo, que a regressão logística não funciona bem
- Como vimos, uma alternativa é criar termos polinomiais
- Se tivermos um número pequeno de atributos, a estratégia é adequada, mas e se tivermos, digamos, 100?
- Se adicionarmos termos quadráticos, o número de novos atributos cresce na ordem de O(n2)!
- Se adicionarmos termos cúbicos, o número de novos atributos cresce na ordem de O(n3)!
- Precisamos de outras maneiras de criar modelos complexos.
- Redes neurais (NNs) foram originalmente motivadas como modelos para replicar a funcionalidade do cérebro
- Já que queremos constuir um modelo de aprendizado, porque não imitar o cérebro?
- Nosso enfoque aqui no curso é como um técnica de aprendizado de máquina
- Primeiro modelo nos anos 40 (McCulloch & Pitts)
- Muita euforia, mas limitações levaram a um período de pouco avanço
- Novos avanços entre o fim dos anos 70 e início dos anos 80 provocaram um ressurgimento
- Muito usadas nos anos 80 e 90
- Popularidade diminuiu no final dos anos 90 (falta de recursos computacionais)
- Ressurgimento nos últimos anos com redes profundas
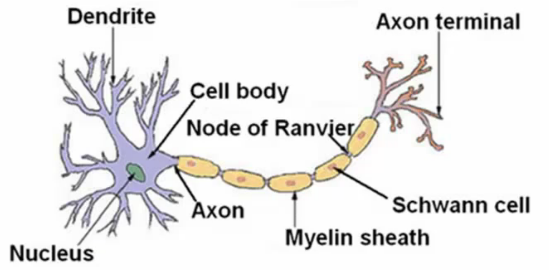
- O neurônio recebe uma ou mais entradas pelos dendritos
- Faz o processamento
- Envia a saída para o axio
- A comunicação é feita por meio de "spikes" elétricos (pulso elétrico pelo axônio para outros neurônios)
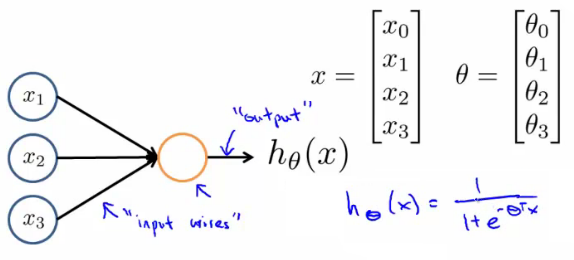
- Em uma rede neural artificial, um neurônio é um unidade logística
- Alimenta a rede pela conexão de entrada
- A unidade logística faz a computação
- Envia a saída pela conexão de saída
- Um modelo muito simplificado da computação de um neurônio real
- Normalmente inclue uma entrada x0, cujo valor é igual a 1
- Essa entrada é chamada de bias (não confundir com o bias-variância)
- Esse é um neurônio com uma função de ativação sigmoide (logistica).
- Outras funções de ativação pode ser usadas
- O vetor θ também é chamado de vetor de pesos do modelo.
- Neurônios aritificiais podem ser combinados em redes neurais
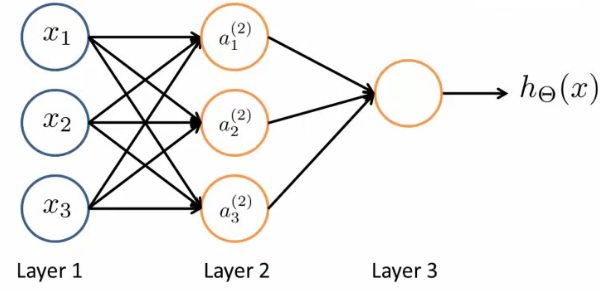
- Primeira camada é a camada de entrada
- Camada finald é a camada de saída
- Ela produz o valor computado pela hipótese
- A(s) camada(s) do meio são chamadas de camadas ocultas
- Não observamos os valores computados nas camadas intermediárias
- Podemos ter mais de uma camada ocultas
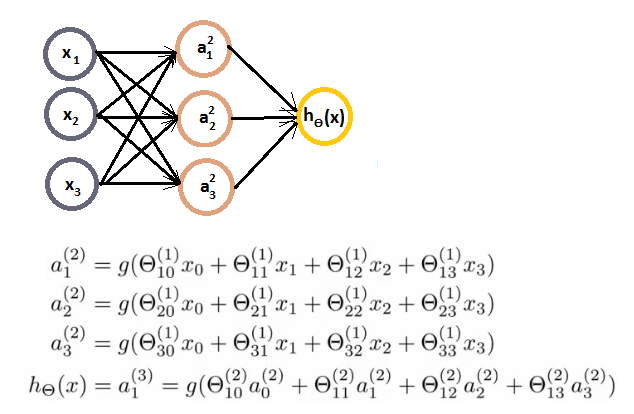
- aij ativação da unidade i da camada j
- a12 é a ativação da 1a. unidade da segunda camada
- Por ativação, nos referimos ao valor que é calculado como saída daquele unidade
- θj matriz de parâmetros controlando a função de mapeamento da camada j para a j+1
- Se a rede tem sj nós na camada j e sj+1 nós na camada j+1, então θj tem dimensões $[s_{j+1}\times s_j+1]
- sj+1 nós na camada (j+1) e sj na camada j mais o bias
- Quais são as computações que ocorrem?
- Temos que calcular a ativação para cada nó
- A ativação depende de
- A(s) entrada(s) de cada nó
- Os parâmetros associados com cada nó (do vetor θ associado a cada camada)
- A implementação (e o entendimento) de uma rede neural pode ser facilitada utilizando vetorização. Vamos definir z12 como
z12=Ɵ101x0+Ɵ111x1+Ɵ121x2+Ɵ131x3
- Que significa a12=g(z12). Similarmente, podemos definir z22 e z32. Podemos definir os vetores:
x=⎣⎢⎢⎡x0x1x2x3⎦⎥⎥⎤z2=⎣⎡z12z22z32⎦⎤
- Podemos vetorizar a computação em 2 etapas:
- z2=θ1x, em que θ1 é a matriz definida anteriormente e x o vetor de entrada
- a2=g(z2), ou seja, aplicamos g() ao vetor z2
- Tendo calculado a2, podemos definir z3 e hθ(x)=a3 como:
- z3=θ2a2, em que θ1 é a matriz definida anteriormente e x o vetor de entrada
- a3=g(z3), ou seja, aplicamos g() ao vetor z3
- Este processo é chamado de propagação forward
- Começa com a ativação da camada de entrada, i.e., o vetor x como entrada
- Propaga para frente e calcula a ativação de cada camada sequencialmente
- Essa é uma versão vetorizada da implementação
- A última camada é uma regressão logistica
- Mas ao invés de ser aplicada aos atributos originais, ela é aplicada à saída aˆ2 da camada anterior. O mesmo acontece com a camada anterior
- Dessa maneira, ao invés de estar restrita aos atributos de entrada, a rede neural pode "aprender" seus próprios atirbutos para a regressão logística
- Dependendo dos parâmetros de cada camada, podemos aprender combinações interessantes!
- As camadas oculta fazem o papel de criar novos atributos, ao invés de criamos manualmente como fazíamos anteriormente
- Além da rede vista aqui, outras arquiteturas (topologias) são possíveis
- Mais/menos nós por camada
- Mais chamadas
- Outras funções de ativação
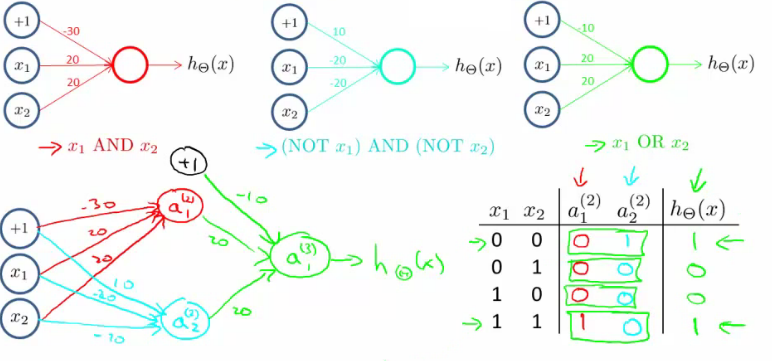
- Um exemplo simples de um problema de classificação não linar é o ou exclusivo (xor)
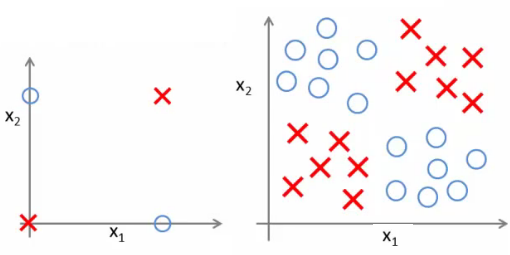
- Esta função não pode ser computada utilizando somente um neurônio
AND
- Vamos começar pelo exemplo de predizer x1 AND x2, que é o operador
e lógico e só é verdade se ambos x1 e x2 são 1.
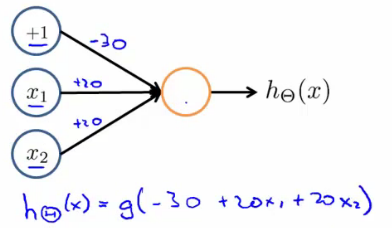
- Depois do treinado, os pesos convergem para
Θ(1)=[−302020]
AND
hΘ(x)=g(−30+20x1+20x2)x1=0 and x2=0 then g(−30)≈0x1=0 and x2=1 then g(−10)≈0x1=1 and x2=0 then g(−10)≈0x1=1 and x2=1 then g(10)≈1
- Similarmente, podemos criar uma rede para calcular o não
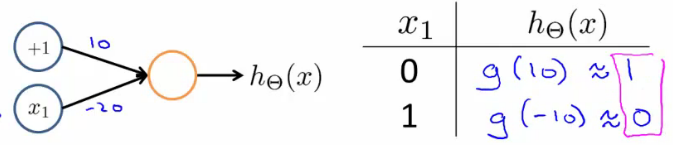
- Podemos combinar as duas para criar o XNOR
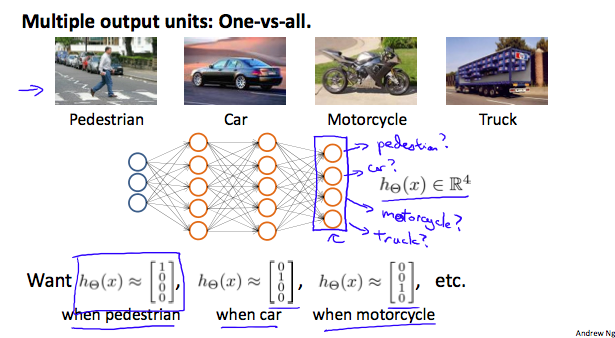
- Uma extensão do "um-contra-todos"
- A saída da rede é um vetor um nó para cada classe
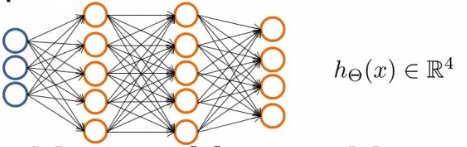
- Redefinimos nossas classes y como um vetor que representa uma classe diferente, com somente um 1 indicando qual é a classe, e 0 nas demais posições

- As camadas internas podem ser representadas como
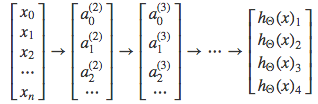
- A hipótese dá um vetor como saída
hΘ(x)=⎣⎢⎢⎡0010⎦⎥⎥⎤
- Que no nosso exemplo é a terceira classe, ou hΘ(x)=3, que representa a moto.