- Máquinas de vetores de suporte são uma outra família de algoritmos de aprendizado de máquina supervisionado
- Em certos casos, é mais simples de usar que redes neurais
- Também tem ótimo desempenho em certas aplicações
- Relembramos da função de custo da regressão logística:
J(θ)=m1i∑m−yilog(hθ(xi))−(1−yi)log(1−hθ(xi))+2mλj=1∑nθ2
- Na regressão logística queremos:
- se y=1, hθ(x)≈1 e θ⊺x>0
- se y=0, hθ(x)≈0 e θ⊺x<0
Quando y=1
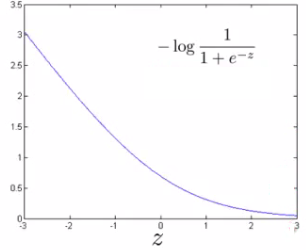
Quando y=0
Quando y=1
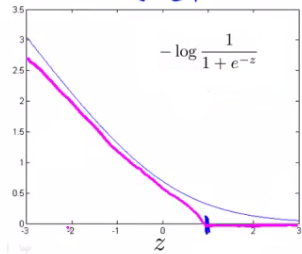
cost1(z)
Quando y=0
cost0(z)
- Removemos m1 (convenção, não altera o mínimo)
- Parâmetro de regularização associado ao primeiro termo (razão mais adiante)
θminCi∑m−yicost1(hθ(xi))−(1−yi)cost0(1−hθ(xi))+21j=1∑nθ2
-
O parâmetro C pode é equivalente a λ1.
- Se quisermos regulizarar mais (reduzir overfitting), decrescemos C
- Se quisermos regularizar menos (reduzir underfitting), aumentados C
-
Ao contrário da regressão logística, a saída de hθ(x) é somente 0 ou 1 (não uma probabilidade)
- Para entender o efeito, vamos considerar um valor de C muito grande
- Nesse caso ∑θ2 predomina na função de custo, que resulta no problema
θmins.a.21i∑nθ2θ⊺x≥1 se y=1θ⊺x≤−1 se y=0
- Esse problema corresponde a encontrar a fronteira de decisão que maximiza a margem de separação entre as classes
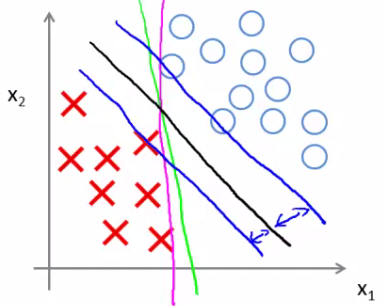
- O parâmetro de regularização C ajuda a contornar outliers
C adequado
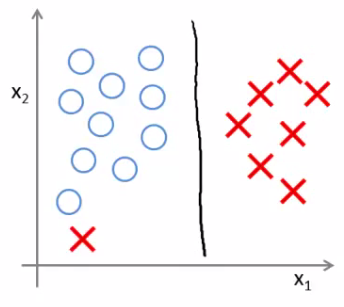
C muito grande
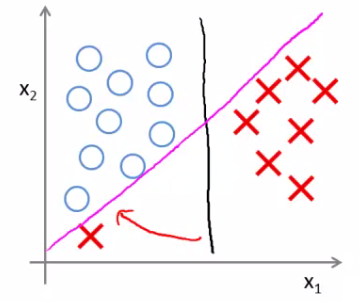
- Por que a margem é maximizada?
- Vamos analisar intuitivamente
- Vamos considerar um problema com 2 dimensões (é mais fácil desenhar)
- Vamos desconsiderar θ0 por hora
- Vamos considerar também um problema linearmente separável
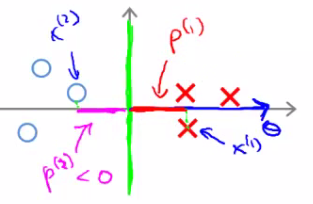
- O que θ⊺x faz?
θ⊺xi=[θ1θ2][x1ix2i]=θ1x1+θ2x2=⟨θ,xi⟩=pi∥θ∥
- em que ⟨θ,xi⟩ é o produto interno entre θ e xi, e pi é o comprimento da projeção de xi em θ.
- As restrições
θ⊺x≥1 se y=1θ⊺x≤−1 se y=0
podem ser reinterpretadas como
pi∥θ∥≥1 se y=1pi∥θ∥≤−1 se y=0
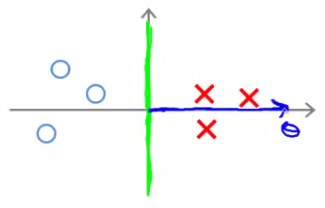
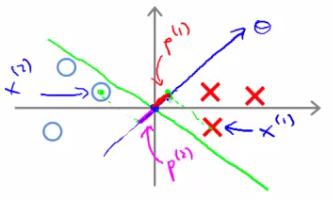
- Se a margem entre as classes for pequena
Margem pequena
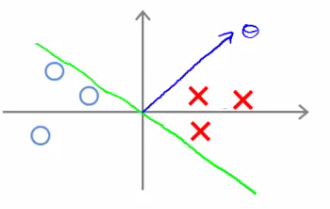
Projeção pequena
-
Se p é pequeno, ∥θ∥ tem que ser grande para garantir as restrições.
-
Mas queremos minimizar ∥θ∥2!
-
Maximizar p minimiza ∥θ∥
- Inicialmente ignoramos θ0
- A fronteira de decisão deve passar obrigatóriamente pela origem
- Se θ0 puder assumir outros valores, não temos a restrição da fronteira de decisão passar pela origem
- Os princípios gerais continuam os mesmos
- O kernel é útil quando queremos computar uma fronteira de decisão não linear
- A ideia consiste em calcular um novo espaço de atributos
- Já fizemos algo parecido quando usamos polinômios a partir do conjunto original de atributos
- Kernels são uma outra maneira de fazer isso
- Considere que temos 3 pontos de referencia l1, l2 e l3
-
Vamos agora definir 3 novos atributos f1, f2 e f3 com base em l1, l2 e l3 tal que:
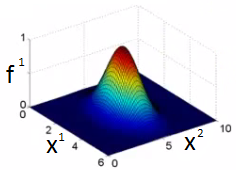
fi=exp(−2σ2∥x−li∥)
-
Essa função de similiradade é chamada de kernel gaussiano
- Como essa funções influenciam na hipótese?
- Vamos supor que σ=[−0.5,1,1,0]
h:=θ0+θ1f1+θ2f2+θ3f3≥0
−0.5+1+0+0=0.5
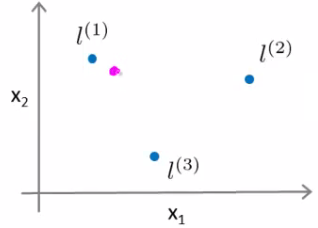
magenta é classificado como 1
−0.5+0+0+0=−0.5
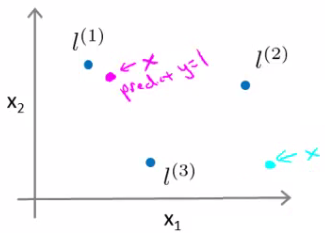
verde é classificado como 0
- Dentro da região marcada como vermelho é classificado como 1
- Fora é classificado como 0
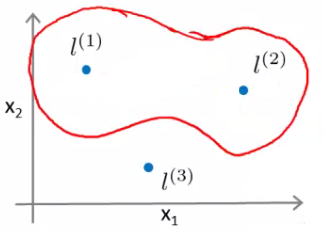
- Podemos usar cada exemplo do conjunto de treinamento como um ponto de referência
- Cada novo atributo mede o quão próximo um novo exemplo está dos pontos do conjunto de treinamento
- Podemos usar SVM para aprender os valores de θ associados a cada novo atributo
- Isso nos leva a nova função de custo
θminCi∑m−yicost1(hθ(fi))−(1−yi)cost0(1−hθ(fi))+21j=1∑mθ2
- O calculo de θ2 é normalmente implementado como θ⊺θ
- Isso permite usar alguns truques como θ⊺Mθ
- M depende do kernel
- Calcula uma variação desse termo de maneira mais eficiente
- Linear (não usar kernel)
- Polinomial (parecido com a ideia de usar polinômios de maior grau)
- String
- X2
- Intersecção de histograma
Cada um tem um conjunto própio de parâmetros
- Não é trivial implementar (não podemos usar a minização do gradiente diretamente)
- Diversos pacotes provêem implementações eficientes
- Multiplos Kernels
- Variações multiclasse
- Diferentes abordagens de otimização